GPU passthru in Proxmox for OpenCL, ufff
Finally I got it working. I think so. This Proxmox installation is simple one, just single node for experiments which is half part. The other part is VM configuration. You may ask, what exactly for do I need GPU in VM? I may need because the hardware is capable of running several additional GPUs and I can use all of them at once in different configurations and even in different operation systems. Just like people do in cloud environments and this setup mimics such thing running server-like computer with datacenter-like GPUs on board. During this test I used NVIDIA GTX 650 Ti which is consumer grade card, but now I confirm to have it working so I will put there my other cards, like NVIDIA Tesla K20xm or FX 5800 with lot more shaders/cores which can be used in OpenCL applications for AI/ML. And you will see how easy is to cross the temperature maximum of a GPU.
Table of Contents
Proxmox configuration
GRUB
First thing to modify is GRUB options. So:
GRUB_CMDLINE_LINUX_DEFAULT="quiet intel_iommu=on initcall_blacklist=sysfb_init video=efifb:off video=vesa:off video=simplefb:off kvm.ignore_msrs=1 vfio_iommu_type1.allow_unsafe_interrupts=1 modprobe.blacklist=radeon,nouveau,nvidia,nvidiafb,nvidia-gpu vfio-pci.ids=10de:11c6,10de:0e0b"
I have Intel Xeon E5645 so in my options I put intel_iommu. In case you have AMD or something else, then it should be adjusted. Blacklisting modules, I prefer to keep all of these as you may want to put different cards in your setup. Without this, Debian (on which Proxmox is run atop) will try to load modules/drivers and put your black console screen in higher resolution. If you blacklist these modules, then you will get low resolution output. That is want you should see here at this moment. Totally variable part is vfio-pci.ids (which can be obtained using lspci command). First one is for video adapter and the second one is for audio device. I put both however I will for sure use only the first one.
Other configurations
Second thing to modify:
root@lab:~# cat /etc/modprobe.d/blacklist.conf
blacklist nouveau
blacklist nvidia
Third one:
root@lab:~# cat /etc/modprobe.d/iommu_unsafe_interrupts.conf
options vfio_iommu_type1 allow_unsafe_interrupts=1
It seems that this one is redundant as it also appears in GRUB options.
Fourth change:
root@lab:~# cat /etc/modprobe.d/vfio.conf
options vfio-pci ids=10de:11c6,10de:0e0b disable_vga=1
Same here, I think that you can have it either here or in GRUB section.
Then, the modules list which should be enabled:
root@lab:~# cat /etc/modules
# /etc/modules: kernel modules to load at boot time.
#
# This file contains the names of kernel modules that should be loaded
# at boot time, one per line. Lines beginning with "#" are ignored.
vfio
vfio_iommu_type1
vfio_pci
vfio_virqfd
Next thing is to apply GRUB options with either of those commands:
update-grub
proxmox-boot-tool refresh
I am little confused as the official documentation (found here) states that you should do the first one, but actually running this command tells us that we should run the second one intead.
To verify it all of above changed anything at all, reboot your system and then:
dmesg | grep -e DMAR -e IOMMU
If you see message saying “IOMMU enabled” then you are good to go further, otherwise some different configuration should be applied. In my case I got some issue saying that my Intel chipset is unstable with IOMMU remapping so the thing is going to be disabled. So there is need to have this “allow_unsafe_interrupts” option I guess. To verify if you have working IOMMU groups:
find /sys/kernel/iommu_groups/ -type l
You should see some entries here.
Virtual Machine
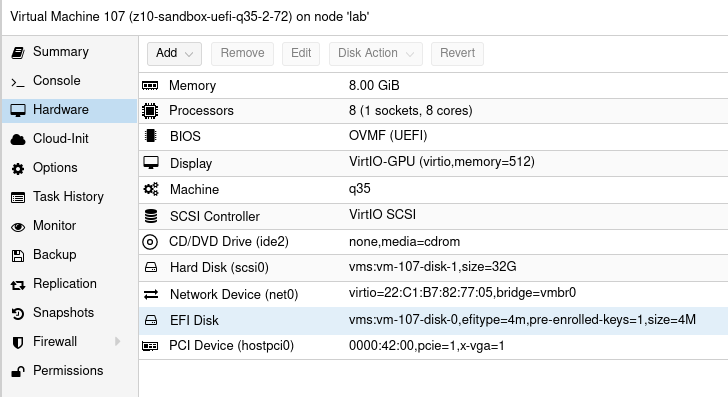
This time I tried 3 VM configurations which is Ubuntu 20 LTS Desktop. There are two main factors you should consider. Different variations may work but it is not fully predictable as you take multiple factors into consideration.
Q35 & UEFI
First one is to use Q35 instead of i440fx. This way you should be able to use PCI-E. I tried it on i440fx and it shows GPU but it is not accessible. Verification process involves the following:
- clinfo showing positive number of platforms
- nvidia-smi showing process list using dedicated GPU
- Ubuntu about page saying that we use particular NVIDIA driver (however it is debatable…)
Second thing is using UEFI instead of default BIOS setup, but it requires you to check if your GPU actually supports UEFI. So I tried Q35 and UEFI and this combination allows us to have all of these somehow working. Regarding UEFI I disabled secure boot in VM UEFI/BIOS.
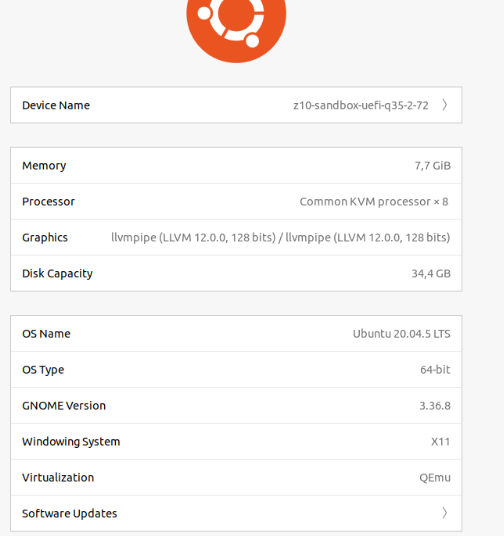
Concerning the driver (NVIDIA in my case) I use nvidia-driver-470-server but other also seems to work. It is weird that Ubuntu about page shows llvmpipe instead of this driver, but the drivers page says that the system uses NVIDIA driver. Not sure who is right here.
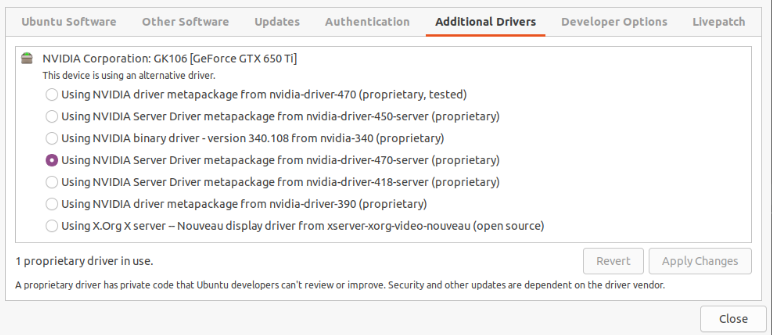
The drivers list:
Device resetting
The last thing which prevents this setup from working is to “remove” the devices at boot time (/root/fix_gpu_pass.sh):
#!/bin/bash
echo 1 > /sys/bus/pci/devices/ID/remove
echo 1 > /sys/bus/pci/rescan
Where ID is PCI-E device ID at VM level which can be checked using lspci -n command. Add it to crontab at reboot time (crontab -e):
@reboot /root/fix_gpu_pass.sh
OpenCL verification
So, if you can see VNC console in Proxmox, your VM is booting and you are able to login, you can install driver, lspci/nvidia-smi/clinfo show proper values then it is now time for a grand last check which is to clone Git repository with my code and try to run it.
cd ~/Documents
git clone https://github.com/michalasobczak/simple_hpc
Then install openjdk-19 and create Application configuration for aiml module having opencl module in your classpath. You may require to rebuild opencl module also. Finally if you are able to see platforms here then you are in the correct place.
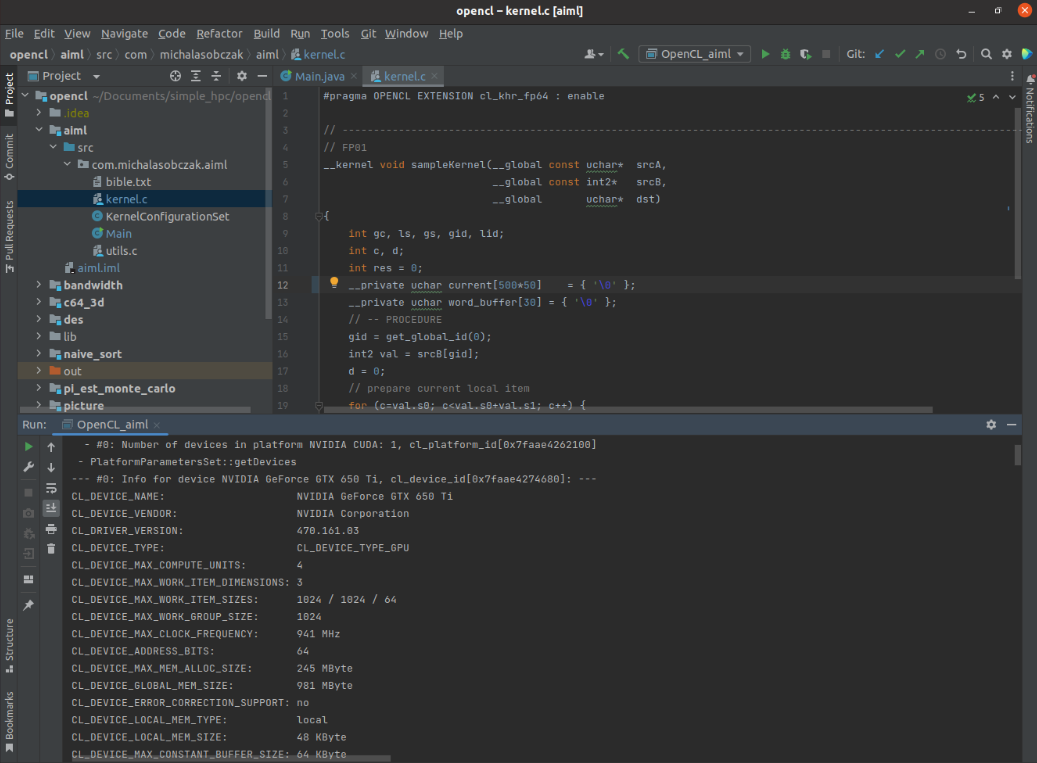
I have NVIDIA GeForce GTX 650 Ti placed in my HP z800 as a secondary GPU and the system recognizesit properly and the code runs well. Performance wise I should say that it seems to be fine. I quickly compared NVS 4200M with this card:
- NVS 4200M (CL2.0 configuration profile): 30 – 40 ms
- GTX 650 Ti (CL3.0 configuration profile): 4 – 5 ms
There is one culprit regarding diagnostics as nvidia-smi does not show GPU utilization and process list, but it shows memory consumption. Increasing local variables size (arrays) has direct relation on memory utilization increase that is why I assume it still works somehow! Maybe even not that bad.
Burning Tesla K20xm
As mentioned earlier after successful setup with consumer GPU it is now time to try a datacenter one. I have this Tesla K20xm which is quite powerful even in today standard. It has plenty of memory (6GB) and tons of cores (2688), even more than my RTX 3050 Ti (2560). Of cource being a previous generation hardware it will be less efficient and will drain more power. And there it is the problem. This GPU can draw up to 235W. I have over 1000W power supply but there is certain limitation on PCI-E gen 2 power output. So the maximum I’ve seen on this GPU during passtru tests was 135W. After few minutes temperature rises from 70 up to 100 degrees Celcius cauing system to switch it off… running nvidia-smi gives me such a error message, asking me nicely to reboot:

So there it is, I forgot totally that this GPU belongs to proper server case with extremely loud fans which I lack actually in PCI-e area in HP z800. This computer has plenty of various fans, even on memory modules, but this area is not covered at all. After computer reboot GPU comes back to life. Besides the problem with the temperature itself, there is efficiency drop after cross somewhere near 90 degrees, it slows down few times and near 100 degress is switches off completely.
Further reading & troubleshooting
- https://pve.proxmox.com/wiki/Pci_passthrough
- https://forum.proxmox.com/threads/gpu-passthrough-to-vm-everything-seems-working-but-it-doesnt.107881/
- https://theorangeone.net/posts/lxc-nvidia-gpu-passthrough/
- https://forum.proxmox.com/threads/problem-with-gpu-passthrough.55918/
- https://forum.proxmox.com/threads/vga-passthrough-error-device-does-not-support-requested-feature-x-vga.35727/