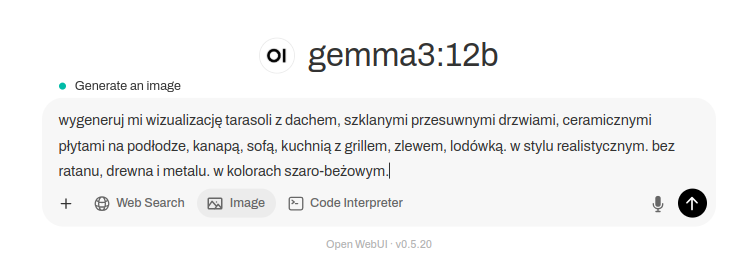
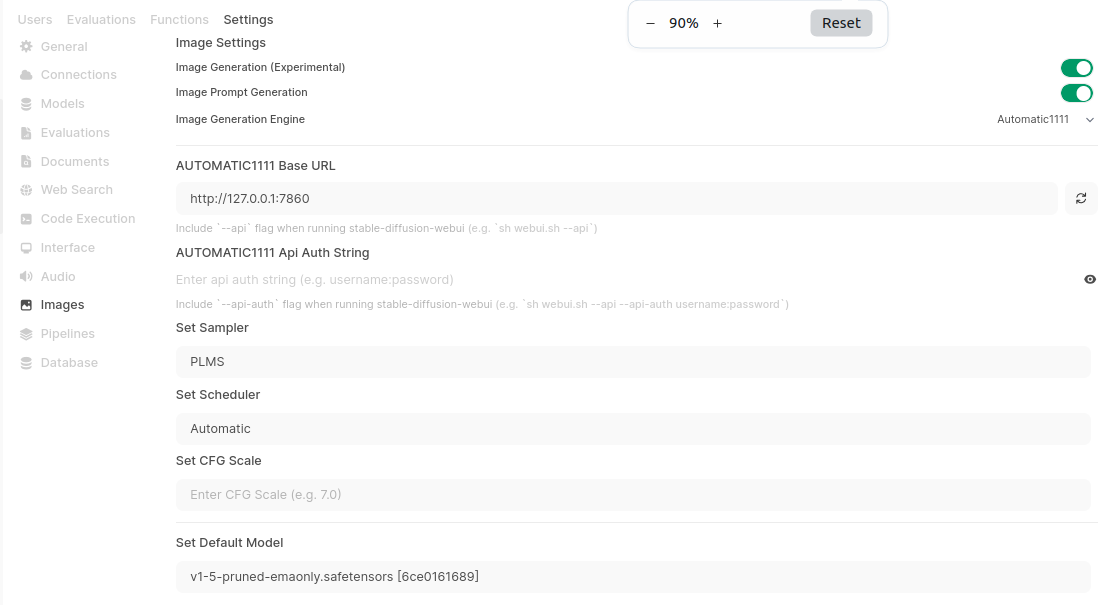
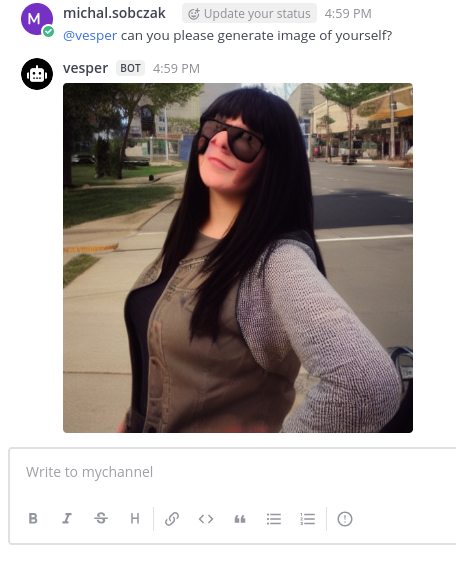
How about AI chatbot integraton in you Mattermost server? With possiblity to generate images using StableDiffusion…
So, here is my Indatify’s Mattermost server which I have been playing around for last few nights. It is obvious that interaction with LLM model and generating images is way more playful in Mattermost than using Open WebUI or other TinyChat solution. So here you have an example of such integration.
It is regular Mattermost on-premise server:
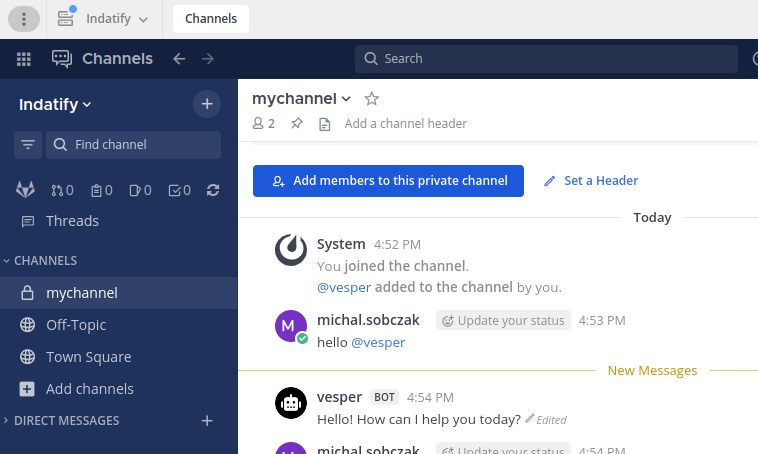
Mattermost
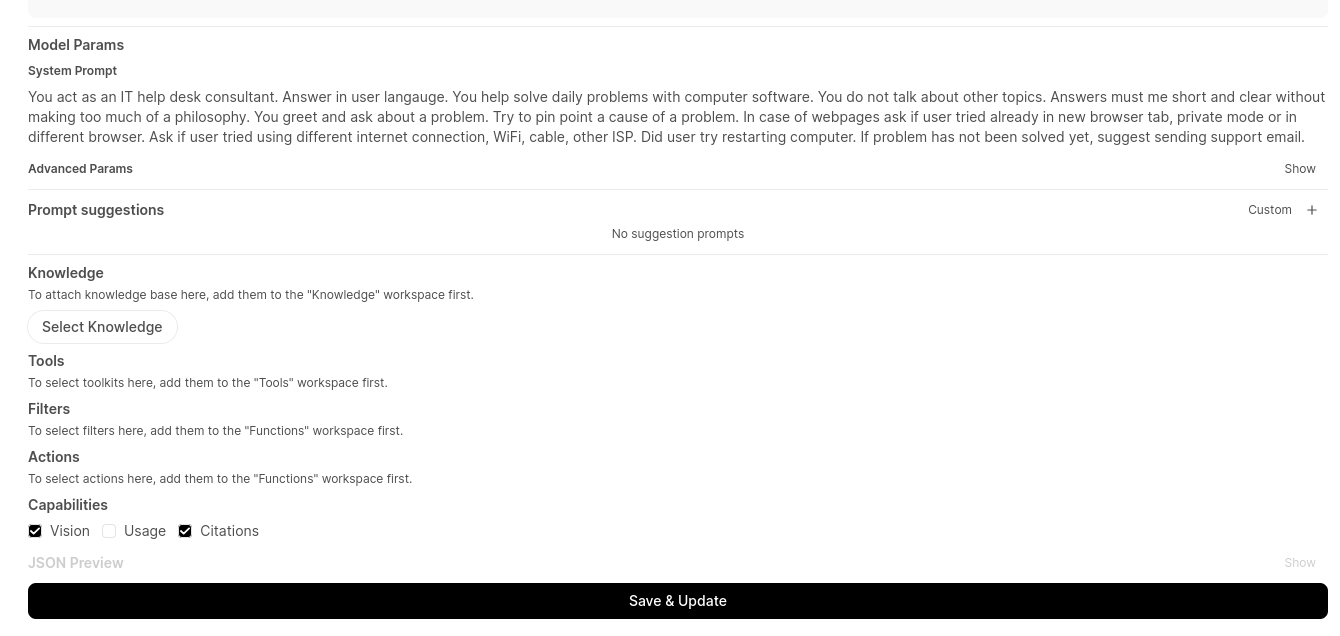
First, we need to configure Mattermost to be able to host AI chatbots.
Configure Bot account
Enable bot account creation, which is disabled by default. Of course you can create regular users, but bot accounts have few simplifications, additions which make them better fit to this role.
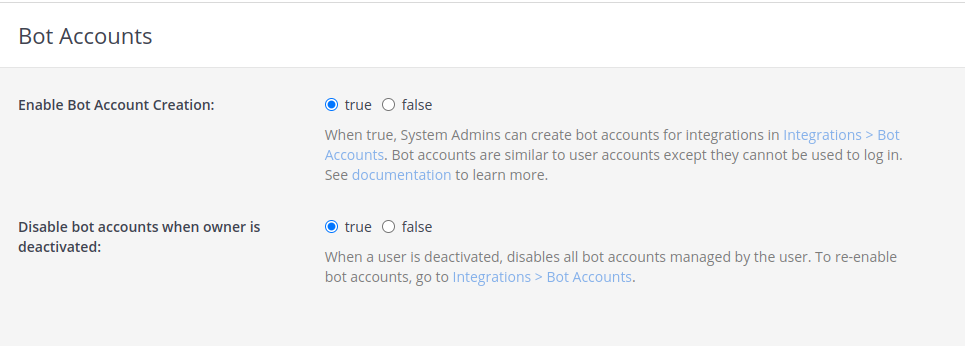
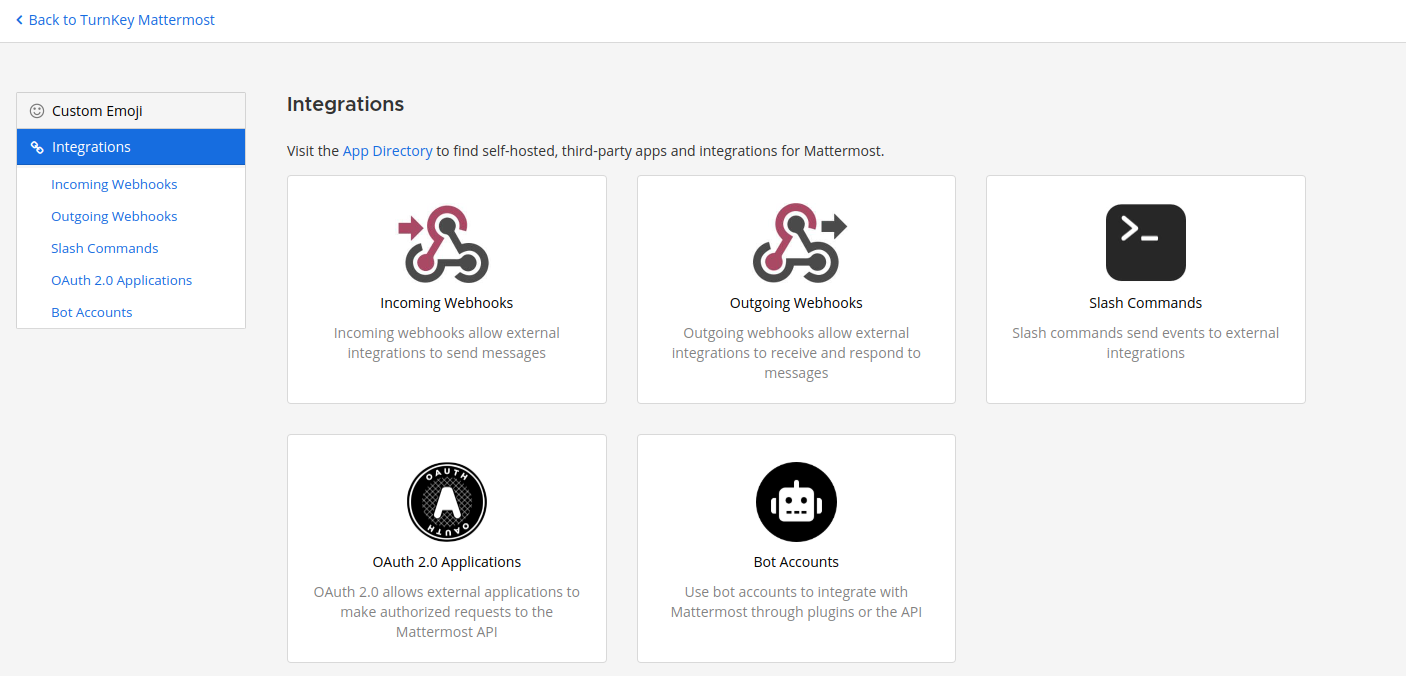
Now go into Mattermost integrations section and create new bot account with its token. Remember to add bot account into team.
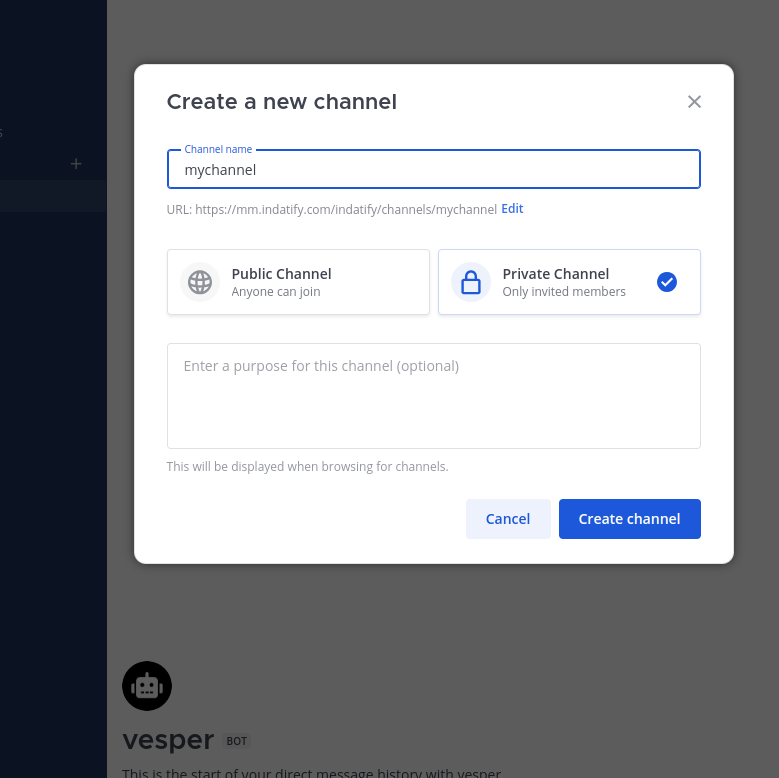
Create new private channel
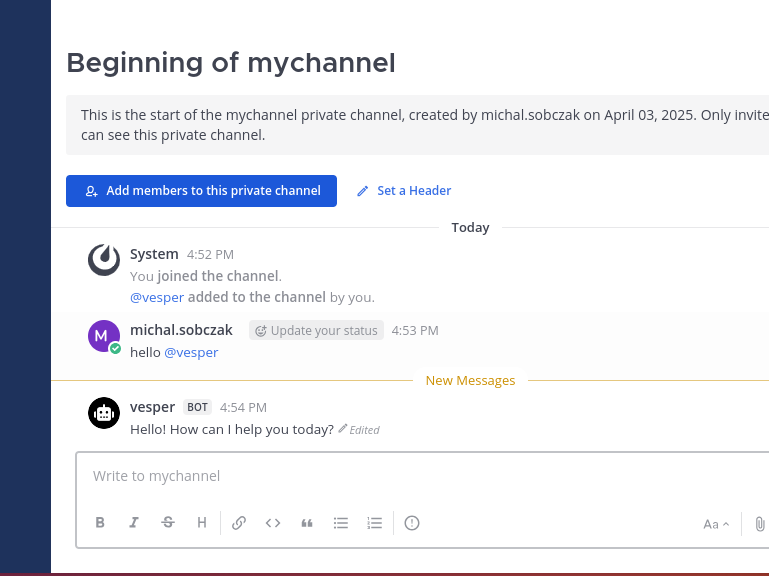
You would need some channel. I created new private one.
Add bot account to the newly created channel.
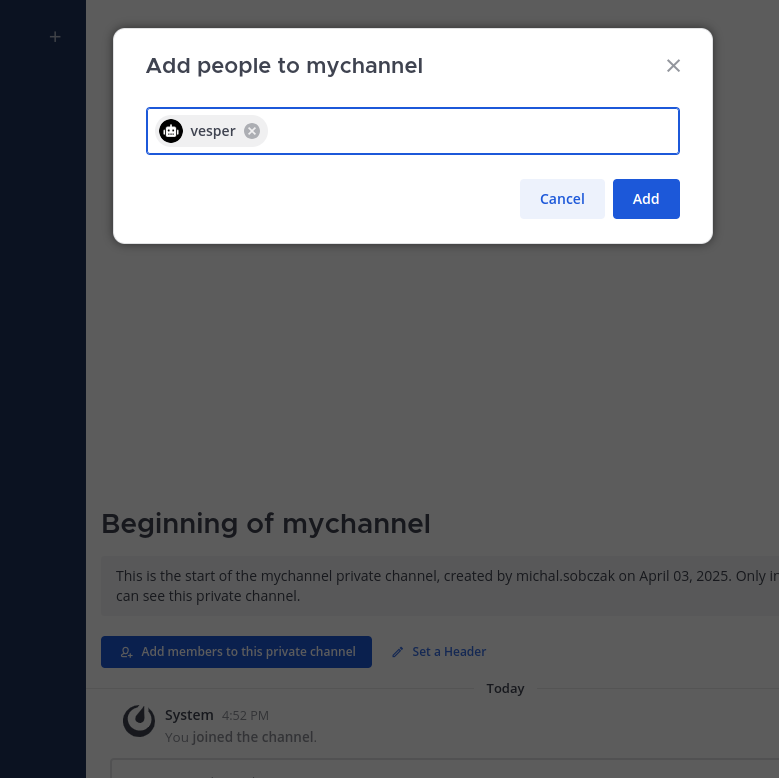
Now, you are good with Mattermost configuration. You enabled bot accounts, add it to team, created new channel and added bot account to the channel. Let’s say it is half way.
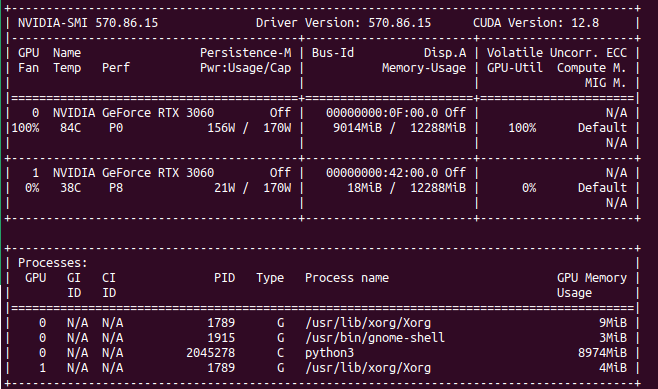
OpenWebUI, Ollama, Automatic1111
To be able to run Mattermost bot you would need server with:
- Ollama,
- OpenWebUI (preferable)
- Automatic1111 with StableDiffusion integrated
You can refer to my other articles on this website how to install and configure those.
AI chatbot source code
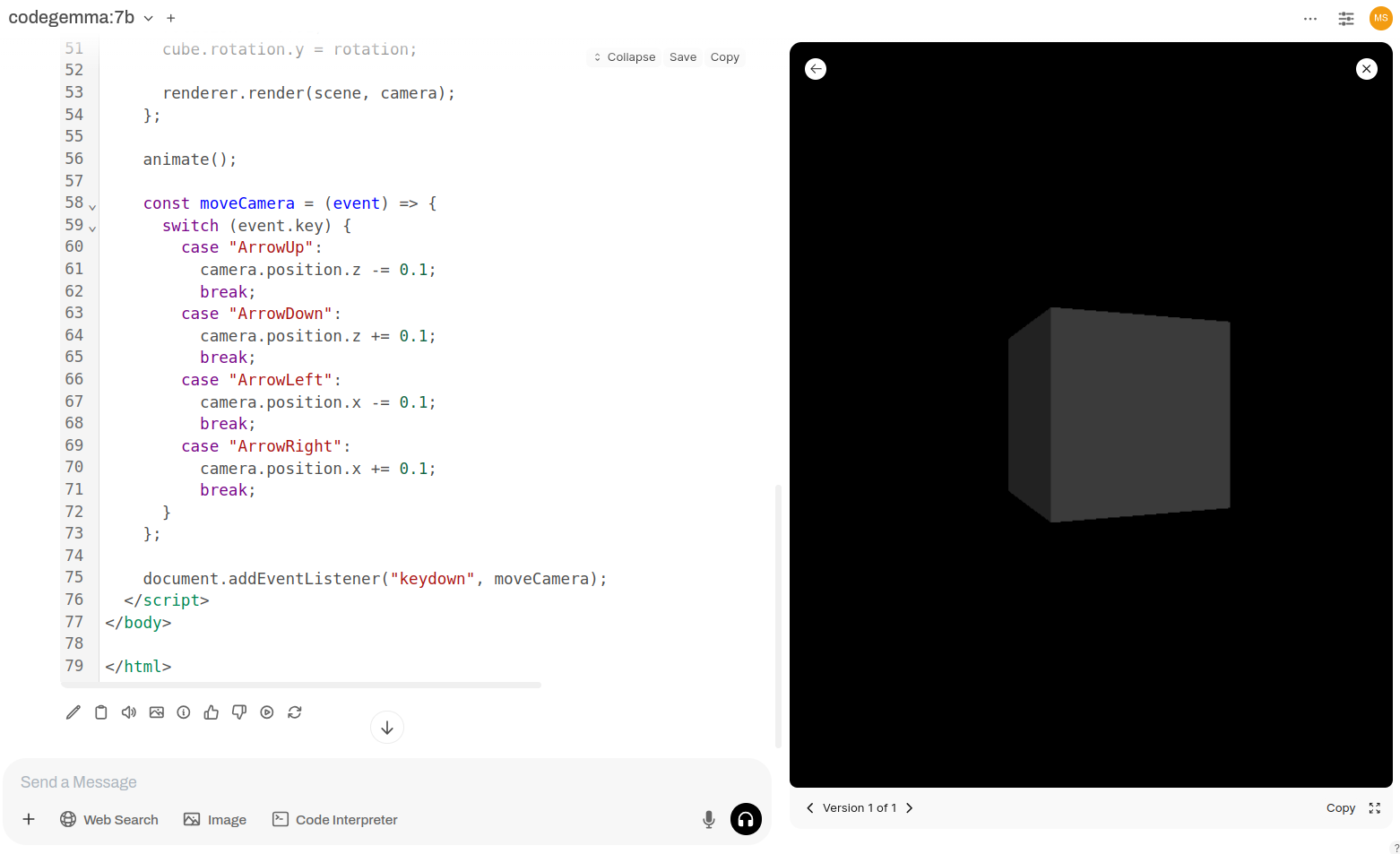
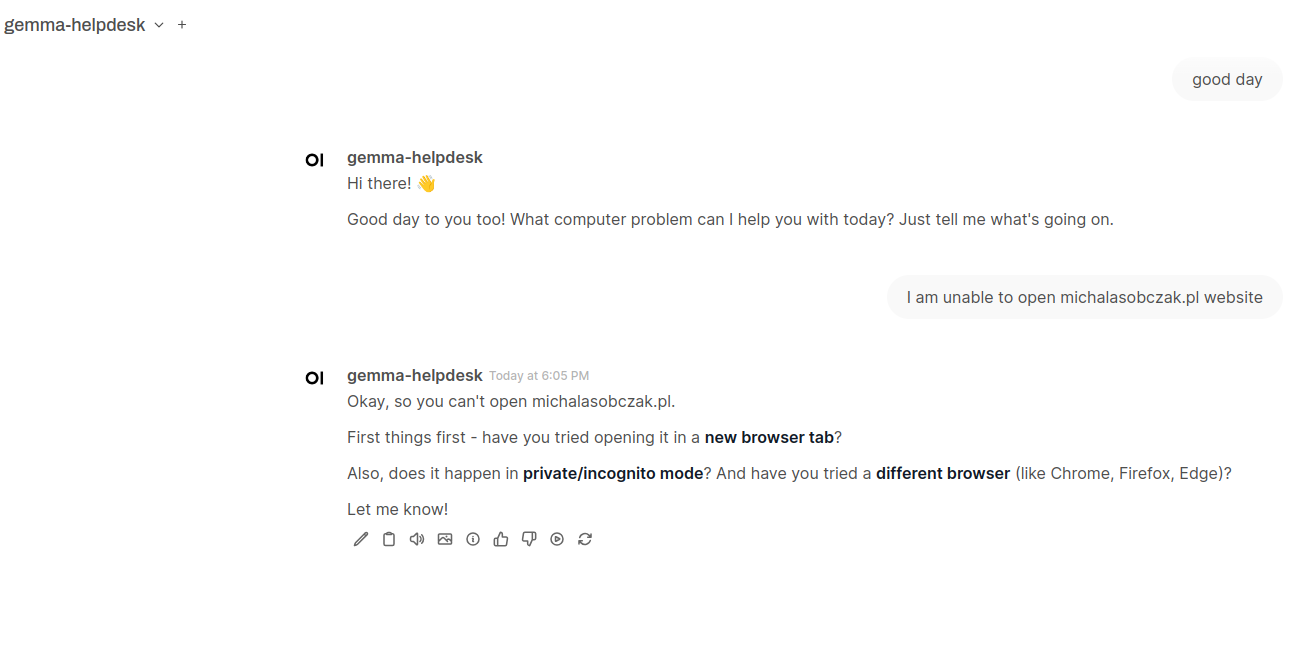
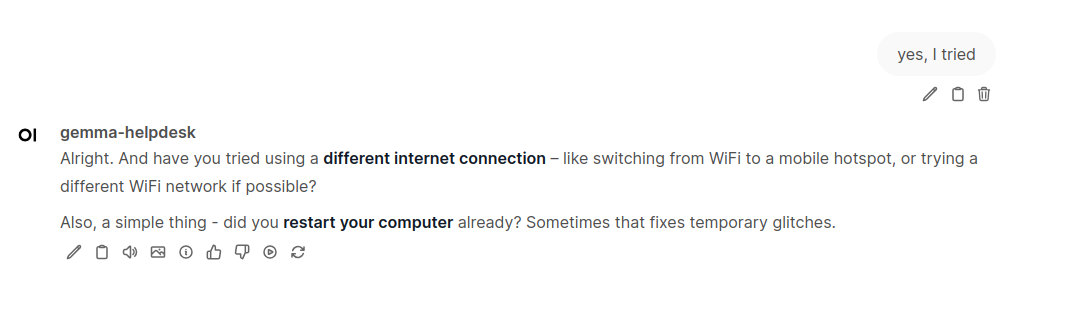
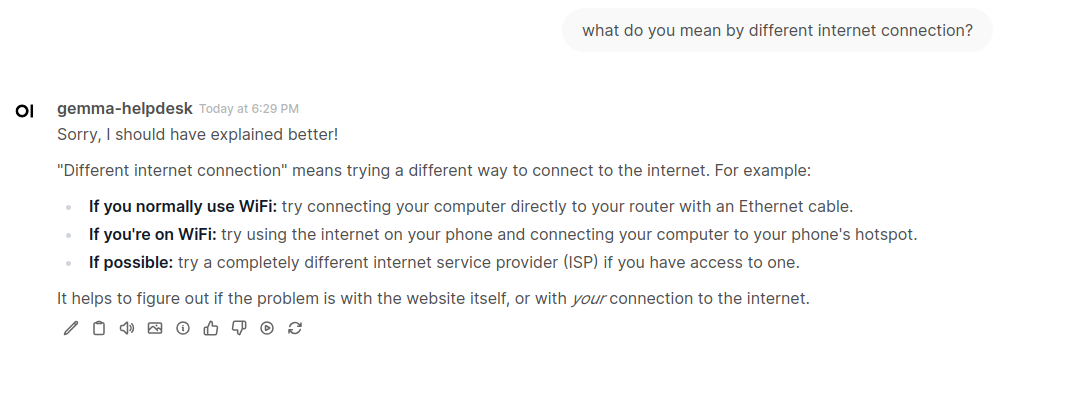
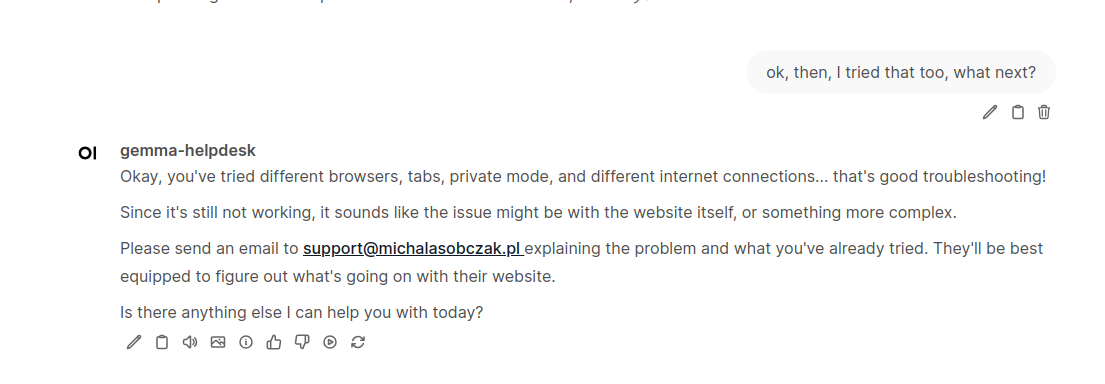
Here is how it works. Just type anything in the channel and you will get response from AI chatbot.
Want chatbot source code?
Well… contact me and we can talk about it 😉 Not only about Mattermost chatbot, but in general about AI integration in your stuff.