For those using ZoneMinder and trying to figure out how to detect objects, there is deepquestai/deepstack AI model and builtin HTTP server. You can grab video frames by using ZoneMinder API or UI API:
https://ADDR/zm/cgi-bin/nph-zms?scale=100&mode=single&maxfps=30&monitor=X&user=XXX&pass=XXX
You need to specify address, monitor ID, user, password. You can also specify single frame (mode=single) or motion (mode=jpeg). Zoneminder uses internally /usr/lib/zoneminder/cgi-bin/nph-zms program binary to grab frame from configured IP ONVIF RTSP camera. It is probably to the most quickest option, but it is convenient one. Using OpenCV in Python you could also access RTSP stream and grab frames manually. However for sake of simplicity I stay with ZoneMinder nph-zms.
So lets say I have such video frame from camera:

It is simple view of street with concrete fence with some wooden boards across. Now lets say I would like to detect passing objects. First we need to install drivers, runtime and start server.
NVIDIA drivers
In my testing setup I have RTX 3050 Ti with 4GB of VRAM running Ubuntu 22 LTS desktop. By default there will not be CUDA 12.8+ drivers available. You can get up to version 550. Starting from 525 you can get CUDA 12.x. This video card has Ampere architecture with Compute Capabilities of 8.6 which translates with CUDA 11.5 – 11.7.1. However you can install drivers 570.86.16 with consists of CUDA 12.8 SDK.
sudo add-apt-repository ppa:graphics-drivers/ppa
sudo apt update
sudo apt install nvidia-driver-570
To check if it is already loaded:
lsmod | grep nvidia
Docker GPU support
Native, default Docker installation does not support direct GPU usage. According to DeepStack you should run the following commands in order to configure Docker NVIDIA runtime. However ChatGPT suggests to install nvidia-container-toolkit. You can find proper explanation of differences here. At first glace it seems that those packages are correlated.
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | \
sudo apt-key add -
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | \
sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update
sudo apt-get install -y nvidia-docker2
sudo pkill -SIGHUP dockerd
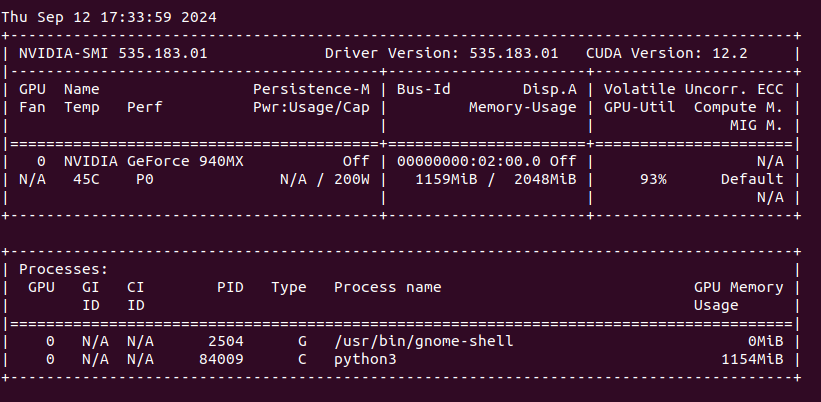
As we installed new driver and reconfigured Docker it is good to fire reboot. After rebooting machine, check if nvidia-smi reports proper driver and CUDA SDK versions:
sudo docker run --gpus '"device=0"' nvidia/cuda:12.8.0-cudnn-devel-ubuntu22.04 nvidia-smi
This should report output of nvidia-smi run from Docker container called nvidia/cuda. Please note that this image may differ a little bit as it changes over time. You can adjust –gpus flag in case you got more than one NVIDIA supported video card in your system.
deepquestai DeepStack
In order to run DeepStack model and API server utilizing GPU just give gpu tag and set –gpus all flag. There is also environment variable VISION-DETECTION set to True. Probably you can configure other things such as face detection, but for now I will just stick with only this one:
sudo docker run --rm --gpus all -e VISION-DETECTION=True -v localstorage:/datastore -p 80:5000 deepquestai/deepstack:gpu
Now you have running DeepStack Docker container with GPU support. Let’s check program code now.
My Vision AI source code
import requests
from PIL import Image
import urllib3
from io import BytesIO
import time
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
prefix = "data-xxx/xxx"
zmuser = "readonly"
zmpass = "readonly"
zmaddr = "x.x.x.x"
zmmoid = x
deepstackaddr = "localhost:80"
#
# DOWNLOAD AND SAVE ZONEMINDER VIDEO FRAME
#
timestamp = int(time.time() * 1000)
url = "https://{}/zm/cgi-bin/nph-zms?scale=100&mode=single&maxfps=30&monitor={}&user={}&pass={}".format(zmaddr, zmmoid, zmuser, zmpass)
output_path = "{}_{}.jpg".format(prefix, timestamp)
response = requests.get(url, verify=False)
if response.status_code == 200:
with open(output_path, "wb") as file:
file.write(response.content)
print(f"Downloaded: {output_path}")
else:
print("Unable to download video frame")
#
# AI ANALYSE VIDEO FRAME
#
image_data = open(output_path,"rb").read()
image = Image.open(output_path).convert("RGB")
response = requests.post("http://{}/v1/vision/detection".format(deepstackaddr),files={"image":image_data},data={"min_confidence":0.65}).json()
#
# PRINT RECOGNIZED AND PREDICTED OBJECTS
#
for object in response["predictions"]:
print(object["label"])
print(response)
#
# CROP OBJECTS AND SAVE TO FILES
#
i = 0
for object in response["predictions"]:
label = object["label"]
y_max = int(object["y_max"])
y_min = int(object["y_min"])
x_max = int(object["x_max"])
x_min = int(object["x_min"])
cropped = image.crop((x_min,y_min,x_max,y_max))
cropped.save("{}_{}_{}_{}_found.jpg".format(prefix, timestamp, i, label))
i += 1
With this code we grab ZoneMinder video frame, save it locally, pass to DeepStack API server for model vision detection and finally we take predicted detections with text output as well as cropped images showing only detected artifacts. For instance, the whole frame was as following:

And automatically program detected and cropped the following region:

There are several, few tens I think, types/classes of object which can be detected by this AI model. It is already pretrained and I think it is closed in terms of learning and correcting detections. I will further investigate that matter of course. Maybe registration plates OCR?