In previous article about GPU pass-thru which can found here, I described how to setup things mostly from Proxmox perspective. However from VM perspective I would like to make a little follow-up, just to make things clear about it.
It has been told that you need to setup q35 machine with VirtIO-GPU and UEFI. It is true, but the most important thing is to actuall disable secure boot, which effectively prevents from loading NVIDIA driver modules.
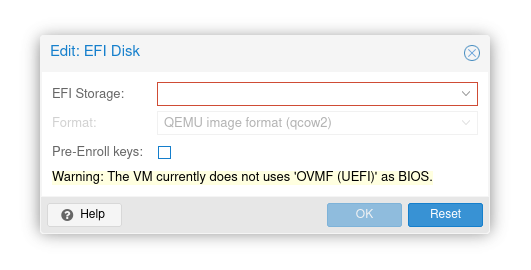
Add EFI disk, but do not check “pre-enroll keys”. This option would enroll keys and enable secure boot by default. Just add EFI disk without selecting this option and after starting VM you should be able to see your GPU in nvidia-smi.
I thought that installing NVIDIA RTX A6000 ADA in default Ubuntu 22 server installation would be an easy one. However, installing drivers from the repository made no good. I verified if secure boot is enable and no it was disabled.
In case you got rid of previously installed drivers, disabled secure boot and installed build tools, kernel headers… you will be good to go to compile driver module. In my case this was the only was to nvidia-smi to recognize this GPU in Ubuntu 22.
slight utlization drop when dealing with multi GPU setup
TLDR
Power usage and GPU utilization varies between single GPU models and multi GPU models. Deal with it.
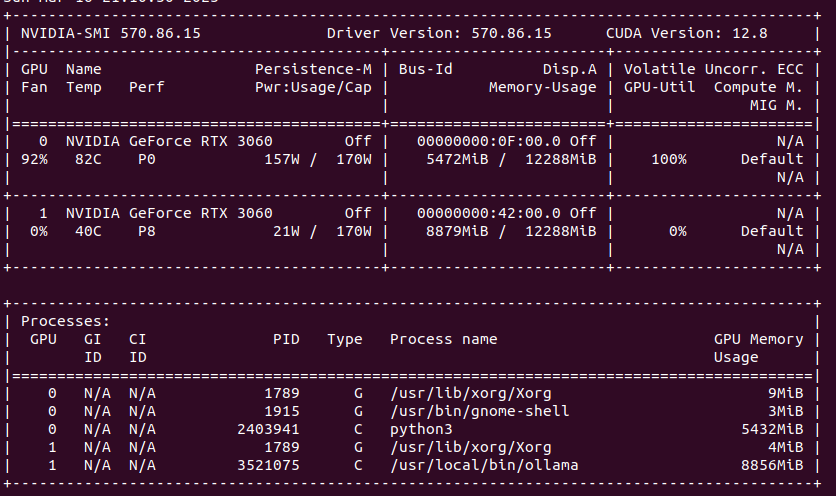
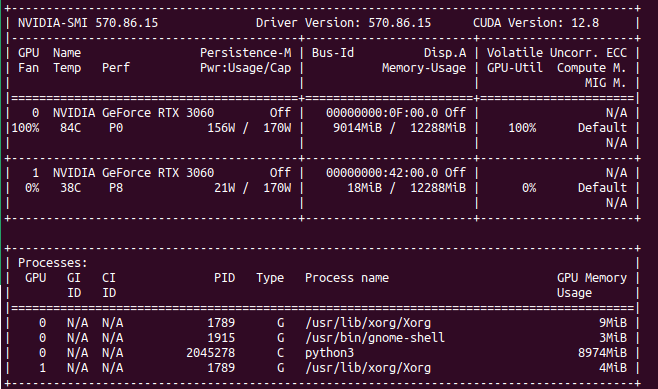
My latest finding is that single GPU load in Ollama/Gemma or Automatic1111/StableDiffusion is higher than using multiple GPUs load with Ollama when model does not fit into one GPU’s memory. Take a look. GPU utilization of Stable Diffusion is at 100% with 90 – 100% fan speed and temperature over 80 degress C.
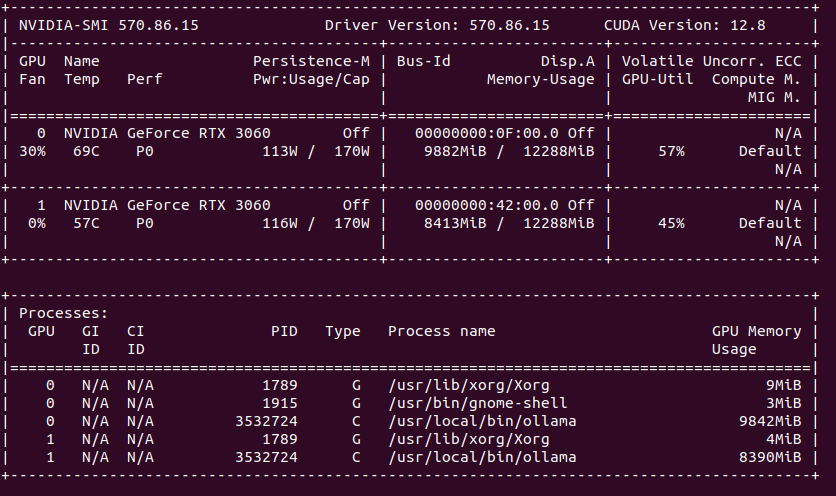
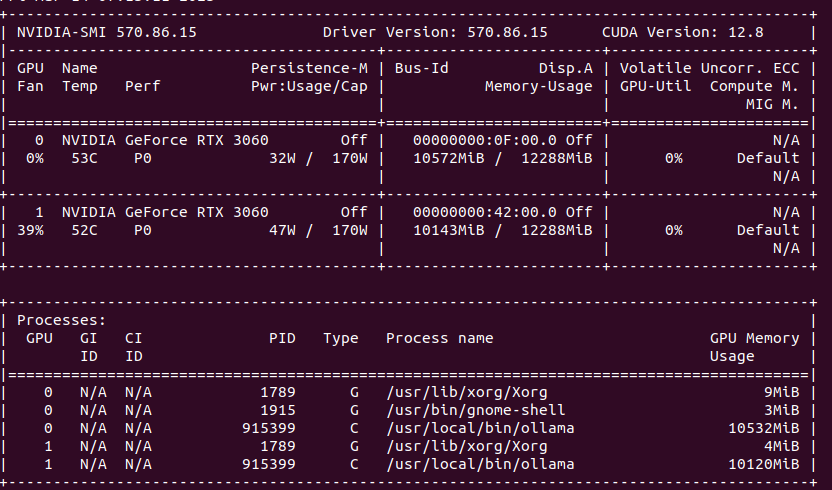
Compare this to load spread across two GPUs. You can clearly see that GPU utilization is much lower, as well as fan speed, temperatures are also lower. In total, power usage is higher comparing to single GPU models.
What does it mean? Ollama uses only that number of GPU which is required, not using all hardware all the time, so this is not something that we can compare to. However it may imply slight utlization drop when dealing with multi GPU setup.
With Ollama paired with Gemma3 model, Open WebUI with RAG and search capabilities and finally Automatic1111 running Stable Diffusion you can have quite complete set of AI features at home in a price of 2 consumer grade GPUs and some home electricity.
With 500 iterations and image size of 512×256 it took around a minute to generate response.
I find it funny to be able to generate images with AI techniques. Tried Stable Diffusion in the past, but now with help of Gemma and integratino with Automatic1111 on WebUI, it’s damn easy.
Step by step
Install Ollama (Docker), pull some models
Run Open WebUI (Docker)
Install Automatic1111 with stable diffusion
Prerequisites
You can find information how to install and run Ollama and OpenWebUI in my previous
Automatic1111 with stable diffusion
Stable Diffusion is latent diffusion model originally created in German universities and later developed by Runway, CompVis, and Stability AI in 2022. Automatic1111 also created in 2022 is a hat put atop of stable diffusion allowing it be consumed in more user-friendly manner. Open WebUI can integrate Automatic1111, by sending text requests to automatic’s API . To install it in Ubuntu 24 you will be to install Python 3.10 (preffered) instead of shipped with OS Python 3.12:
As you can see one uses venv. If your Ubuntu got only Python 3.11 then you are good to go with it. I start Automatic1111 with some additional parameters to help me with debugging things:
./webui.sh --api --api-log --loglevel DEBUG
Open WebUI integration
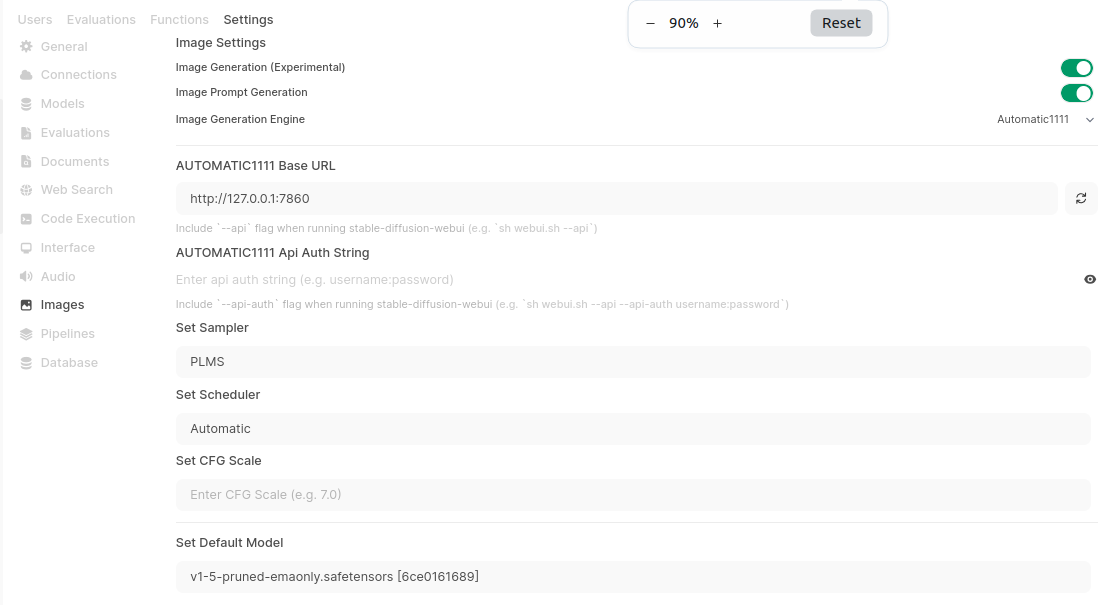
Go to Admin setting and look for “Images”:
Enable image generation, prompt generation and select Automatic1111 as engine. Enter Base URL with should be http://127.0.0.1:7860 by default, in case you run WebUI and Automatic1111 on the same machine. Next are sample, scheduler, CFG scale and model.
I find last two parameters, the most important from user-perspective. Those are image size and number of steps. The last one sets iterations number for diffusion, noise processing. The more you set, the longer it takes to accomplish. Image size also seems to be correlated with final product as it implies how big the output should be.
1000 iterations
Set number of iterations to 1000 and asked to generate visualization. It took around 30 minutes and grew up to 9GB of VRAM.
Result is quite intesting. But I’m not exactly sure what I am looking at. Is it one image or are these two images combined? Frankly speaking, I can wait even and hour to get something useful. Back in 2023 and 2024 I tried commercial services to generate designs and they failed to accomplish even simple tasks. So instead of paying 20 USD or so, I prefer to buy GPU and use some home electricity to generate very similar images. This is just my preference.
Conclusion
I am not going to pay OpenAI. These tools provide much fun and productivity.
Utilize both CPU, RAM and GPU computational resources
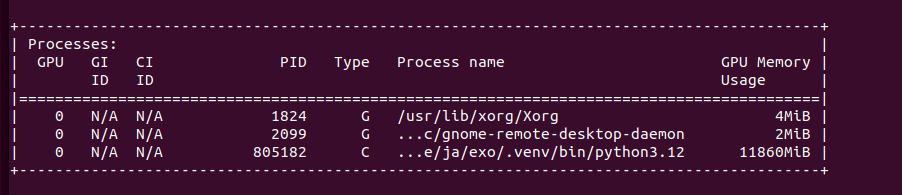
With Ollama you can use not only GPU but also CPU with regular RAM go run LLM models, like DeepSeek-R1:70b. Of course you need to have fast both CPU and RAM and have plenty of it. My Lab setup contains 24 vCPU (2 x 6 cores * 2 threads) and from 128 to 384 GB of RAM. Once started, Ollama allocates 22.4GB in RAM (RES) and 119GB of vritual memory. It occupies 1200% CPU utilization causing system load to go up to 12. However, CPU utilization is only 50% in total.
It loads over 20GB in RAM, puts system on load
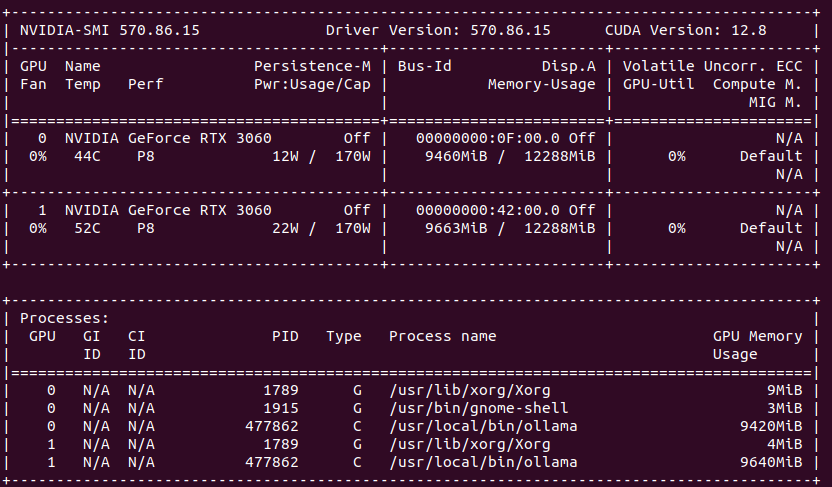
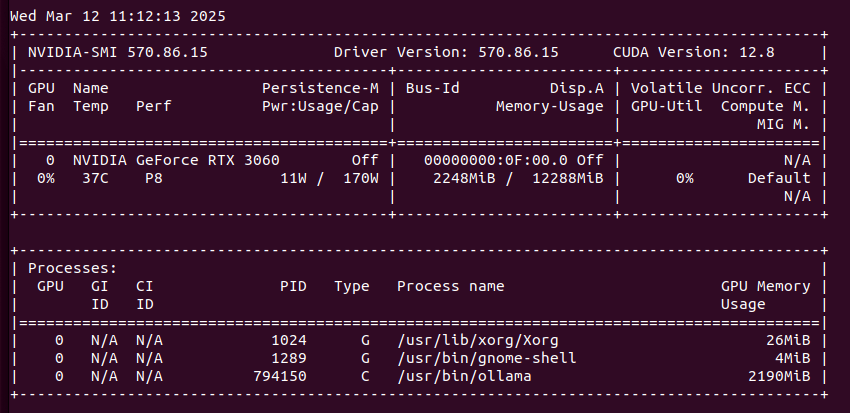
On GPU side it allocates 2 x 10GB of VRAM, but stays silient in terms of actual cores usage.
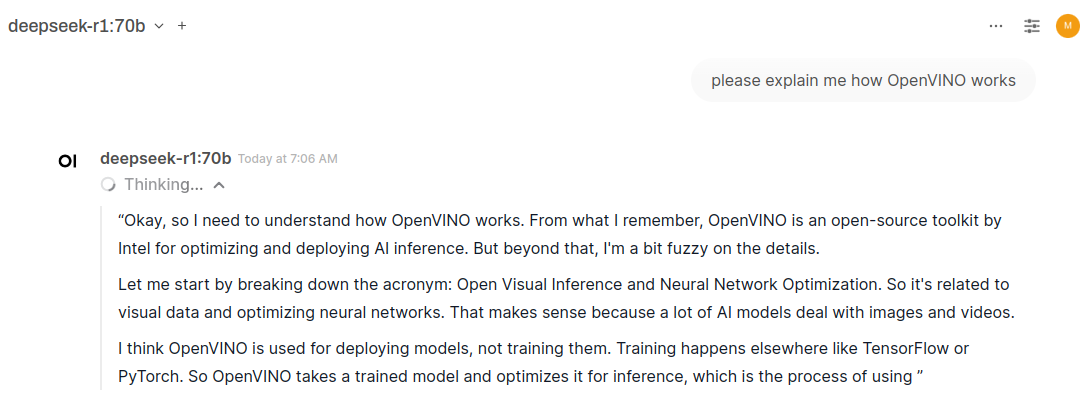
Thinking…
DeepSeek-R1 stars with “Thinking” part, where it makes conversation with itself about its knowledge and tries to better understand questions aloud. It could ask me those questions, but chooses not to and tries to pick whatever it thinks its best at the moment. Fully on CPU at the moment, no extensive GPU usages.
It generates this “Thinking” stage for minutes… and after an hour or so it gave full answer:
Ollama with WebUI on 2 “powerful” GPUs feels like commercial GPTs online
I thought that Exo would do the job and utilize both of my Lab servers. Unfortunately, it does not work on Linux/NVIDIA with my setup and following official documentation. So I went back to Ollama and I found it great. I have 2 x NVIDIA RTX 3060 with 12GB VRAM each giving me in total 24GB which can run Gemma3:27b or DeepSeek-r1:32b.
Gemma3:27b takes in total around 16 – 18GB of GPU VRAM
DeepSeek-r1:32b takes in total around 19GB of GPU VRAM
Ollama can utilize both GPUs in my system which can be seen in nvidia-smi. How to run Ollama in Docker with GPU acceleration you can read in my previous article.
So why running on multiple GPUs is important?
With more VRAM available in the system you can run bigger models as they require to load data into video card memory for processing. As mentioned earlier, I tried with Exo as well as vLLM, but only Ollama supports it seamlessly without any hassle at all. Unfortunately Ollama, as far as I know, does not support distrubuted inference. There has been work under construction way back in Nov 2024, however it is not clear if it is going to be in main distribution.
Running more than one CPU and GPU also requires powerful PSU. Mine got 1100W and can handle 2 x Xeon processors, up to 384 GB of RAM and at least 2 full sized full powered GPUs. Idling it takes around 250 – 300 W. At full GPU power it draws 560 – 600W.
Can I install more than two GPUs?
Yes, we can. However in my Lab computer I do not have more than 2 high power PCI-E slots so further card may be underpowed. Still it is quite interesting thing to check out in the near future.
How about Open WebUI?
Instead of using command line prompt with Ollama, it is better in terms of productivity to use web user interface called Open WebUI. It can be run from Docker container as follows:
With WebUI you can modify inference parameters (advanced params).
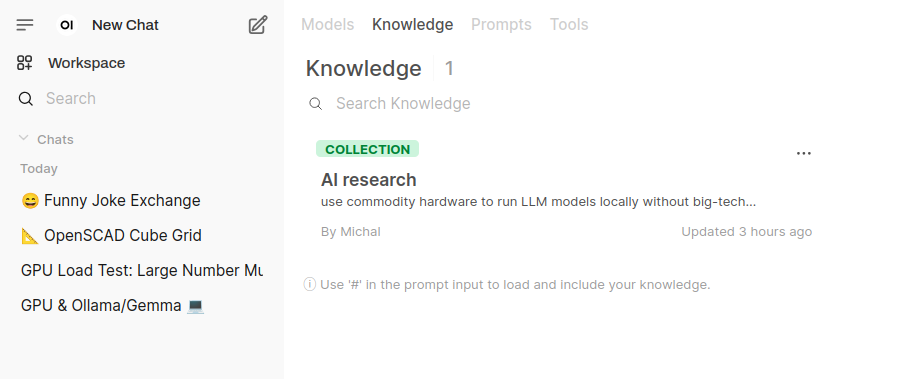
Knowledge base/context
You can build your knowledge context where you can add your knowledge entries. Probably useful when creating custom chat bots.
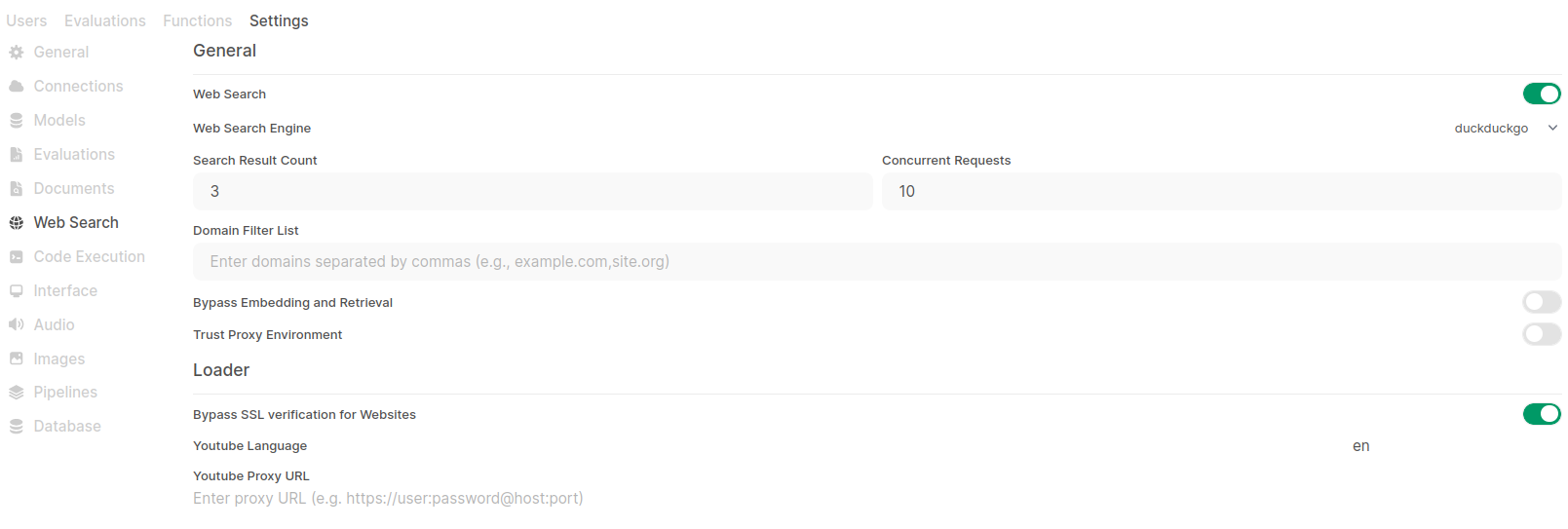
Web search
There is also web search feature. You can define you preferred search engine.
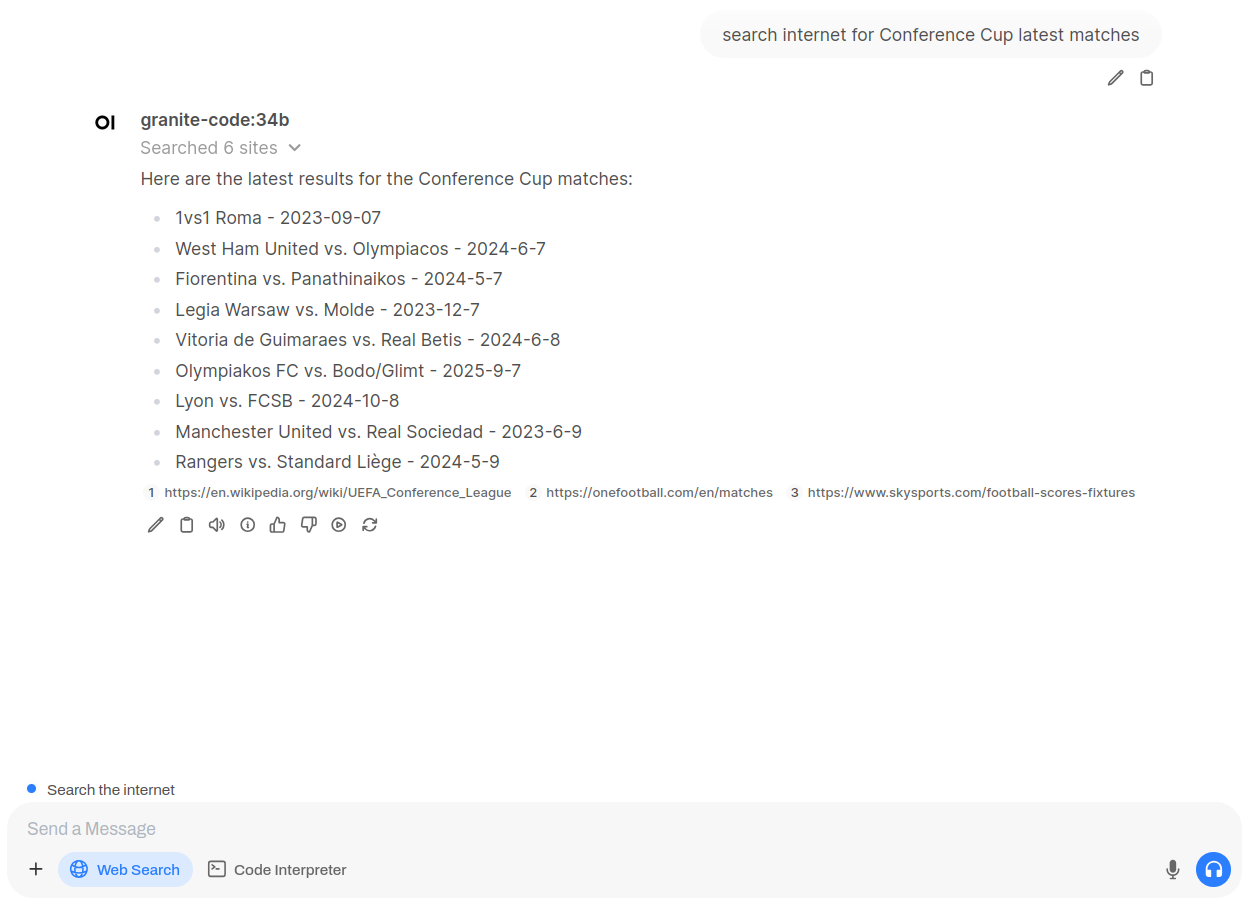
Once set, start new chat and enable search. It will search thru internet for required information. Although it looks funny:
Conclusion
You can use commodity, consumer grade hardware to run your local LLMs with Ollama, even those much more resource hungry by combining multiple GPUs in your machine. Distributed inference with Ollama and Exo requires little more work to be done. I will be searching for further tools across this vast sea of possiblities.
Theory: running AI workload spreaded across various devices using pipeline parallel inference
In theory Exo provides a way to run memory heavy AI/LLM models workload onto many different devices spreading memory and computations across.
They say: “Unify your existing devices into one powerful GPU: iPhone, iPad, Android, Mac, NVIDIA, Raspberry Pi, pretty much any device!“
People say: “It requires mlx but it is an Apple silicon-only library as far as I can tell. How is it supposed to be (I quote) “iPhone, iPad, Android, Mac, Linux, pretty much any device” ? Has it been tested on anything else than the author’s MacBook ?“
So let’s check it out!
My setup is RTX 3060 12 GB VRAM. It runs on Linux/NVIDIA with default tinygrad runtime. On Mac it will be MLX runtime. Communication is over regular network. It uses CUDA toolkit and cuDNN library (deep neural network).
Quick comparison of Exo and Ollama running Llama 3.2:1b
Fact: Ollama server loads and executes models faster than Exo
Running Llama 3.2 1B on single node requires 5.5GB of VRAM. No, you can’t use multiple GPUs in single node. I tried different ways, but it does not work, there is feature request in that matter. T. You should be given chat URL where you can go thru regular web browser. To be sure Exo picks the correct network interface just pass address via –node-host parameter. To start Exo run the following comand:
exo --node-host IP_A
However, the same thing run on Ollama server takes only 2.1GB of VRAM (vs 5.5GB of VRAM on Exo) and can be even run on CPU/RAM. Speed of token generation thru Ollama server is way higher than on Exo.
sudo docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
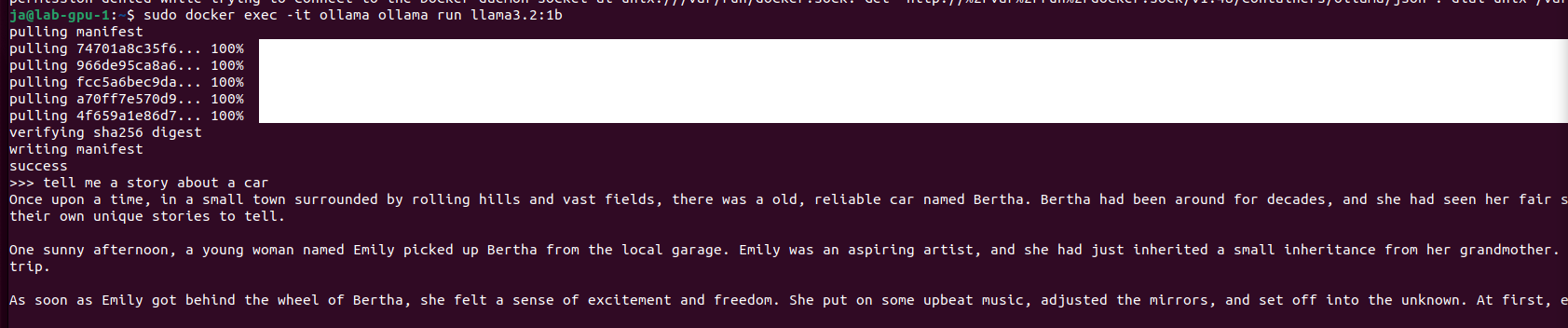
sudo docker exec -it ollama ollama run llama3.2:1b
So, in this cursory (narrow) comparison, Ollama server is ahead both in terms of memory consumption and speed of generation. At this point they both give somehow usable answers/content. Let’s push it to work more harder trying 3.2:3b. Well, first with Exo:
With no luck. It tried to allocate more than 12GB of VRAM in single node. Let’s try it with Ollama server for comparison:
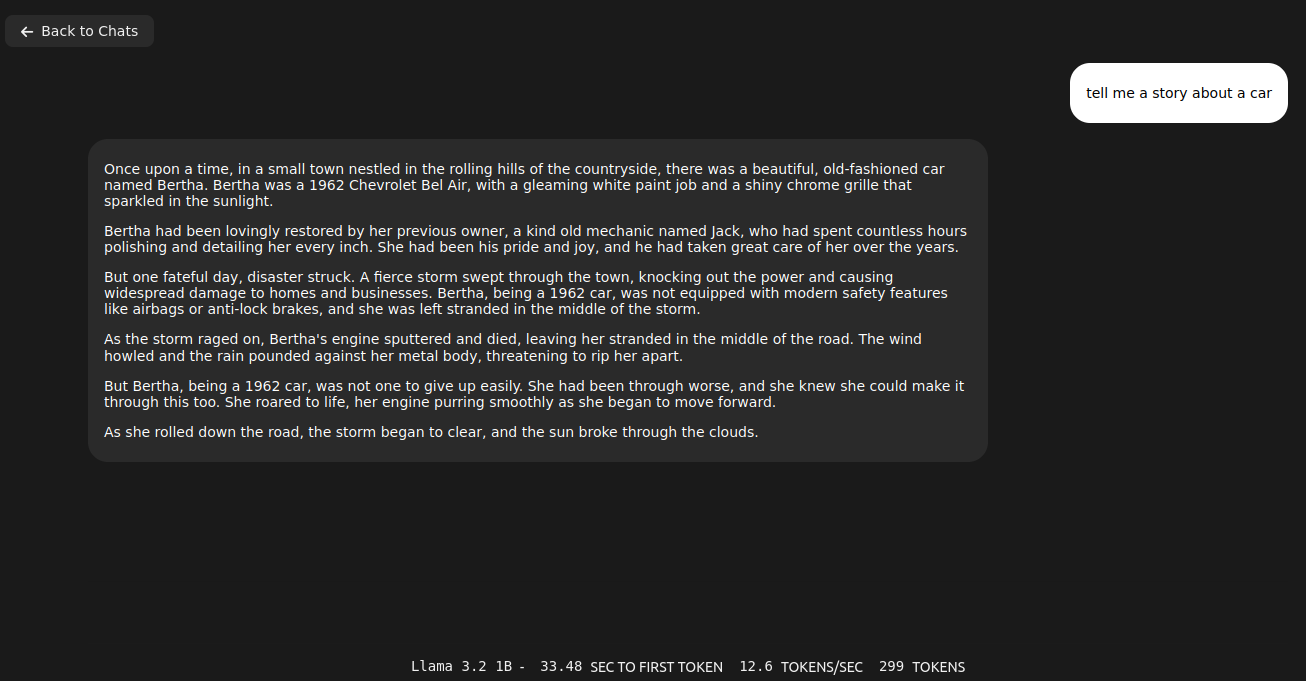
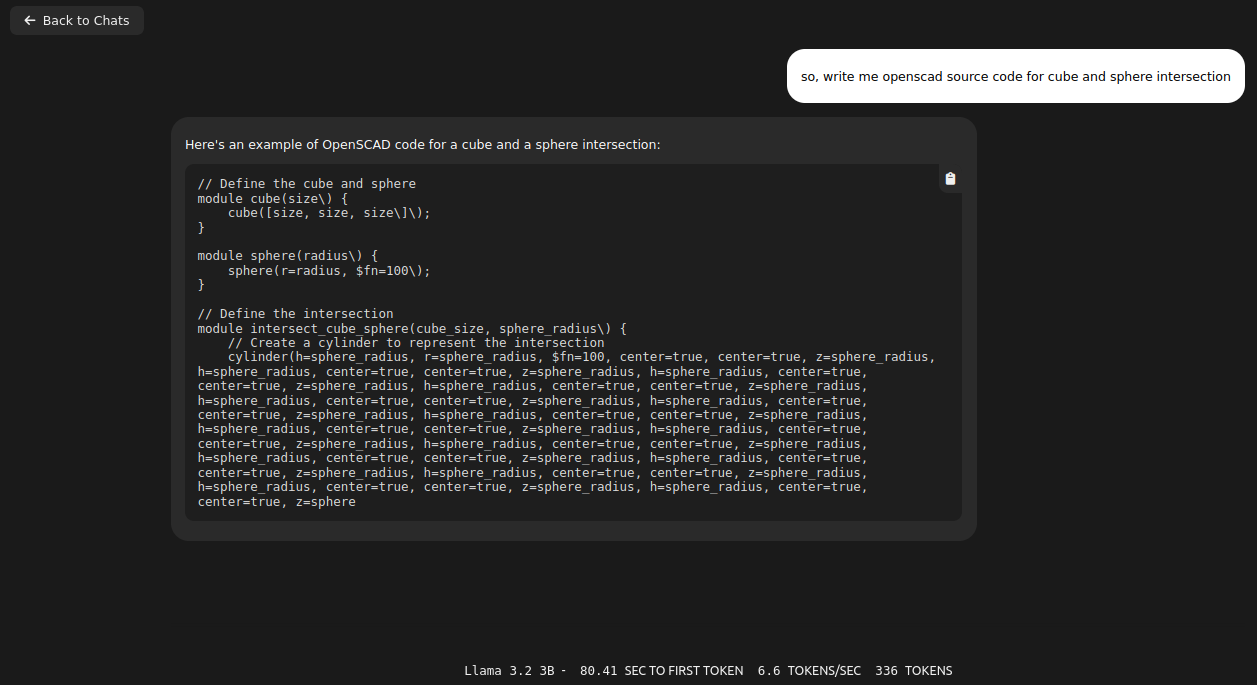
It gave me quite long story. It fit into memory by using only 3.3GB of VRAM. With Llama 3.1:8b it puts 6.1GB of VRAM. It can generate OpenSCAD source code for 3D desigs, so it is quite useful. With Ollama I start even run QwQ with 20B parameters taking 11GB VRAM and 10GB of RAM utilizing 1000% of CPU, which translates losely to 10vCPU at 100%. It can also provide me with OpenSCAD code, however much slower than using smaller models like 3b or 8b Llamas, few seconds comparing to few minutes of generation.
Add second node to Exo cluster
Fact: still absurd results
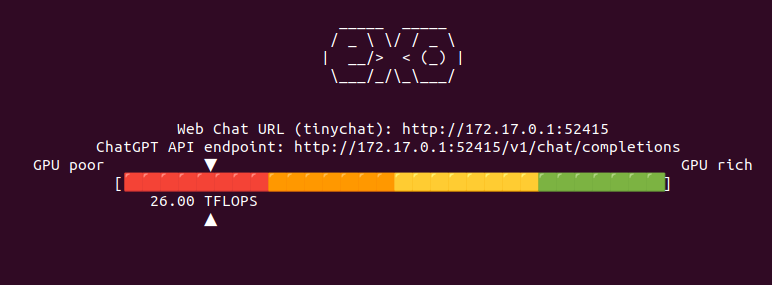
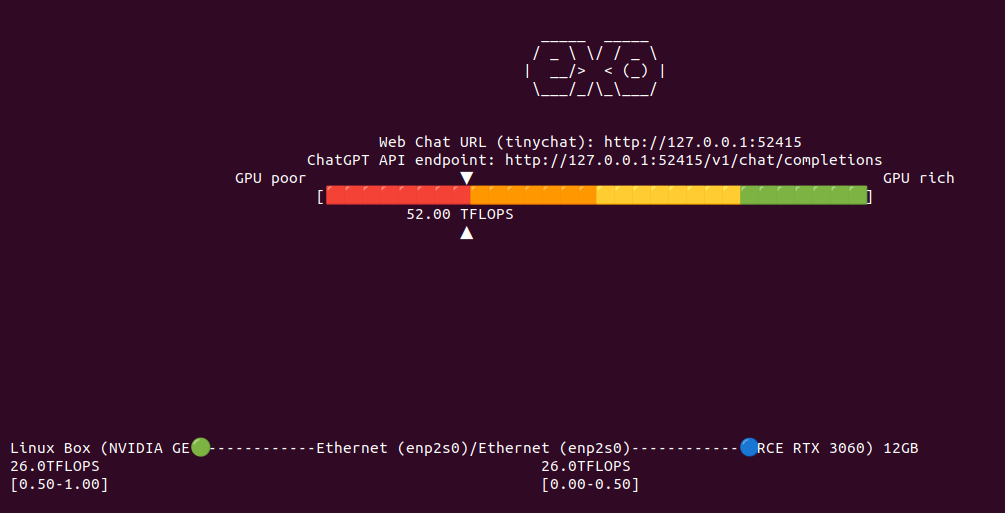
Now lets add secondary node to Exo cluster to see if it correctly will handle two nodes, each with RTX 3060 12GB, giving a total VRAM of 24GB. It says that combined I have 52 TFLOPS. However from Exo source code study I know that this is hard coded:
Same thing with models available thru TinyChat (web browser UI for Exo):
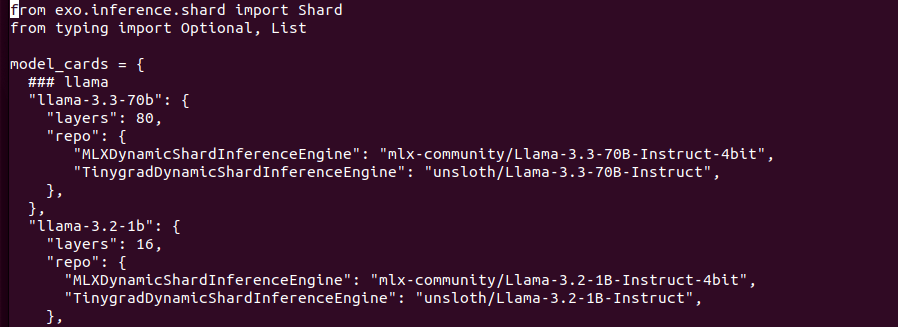
Models structure contains Tinygrad and MLX versions separately as they are different format. Downloading models from HuggingFace. I tried to replace models URL to run different onces, with no luck. I may find similar models from unsloth with same number of layers etc but I skipped this idea as it is not so important to be honest. Lets try with “built-in” models.
So I have now 52 TFLOPS divided into two nodes communicating over network. I restarted both Exo programs to clear out VRAM from previous tests to be sure that we run from ground zero. I aksed Llama 3.2:1B to generated OpenSCAD code. It took 26 seconds to first token, 9 tokens/s, gives totally absurd result and takes around 9GB VRAM in total across two nodes (4GB and 5GB).
Bigger models
Fact: Exo is full of weird bugs and undocumented features
So… away from perfect but it works. Let’s try with bigger model, which does not fit in Exo on single node cluster.
I loaded Llama 3.2:3B and it took over 8GB of VRAM on each node, giving 16GB of VRAM in total. Same question about OpenSCAD code with better results (not valid still…), however still with infinite loop in the end.
I thought that switching to v1.0 tag will be good idea. I was wrong:
There are some issue with downloading models also. They are kept in ~/.cache/exo/downloads folder, but not recognized somehow properly, which leads to downloading it once again over and over again.
Ubuntu 24
Fact: bugs are not because Ubuntu 22 or 24
In previous sections of this article I used Ubuntu 22 with NVIDIA 3060 12GB. It contains Python 3.10 and manually installed Python 3.12 with PIP 3.12. I came across GitHub issue where I found some hint about running Exo on a system with Python 3.10:
So I decided to reinstall my lab servers from Ubuntu 22 into 24.
In result I have the same loop in the end. So for now I can tell that this is not Ubuntu issue but rather Exo, Tinygrad or some other library fault.
Manually invoked prompt
Fact: it mixes contexts and do not unload previous layers
So I tried invoking Exo with cURL request as suggested in documentation. It took quite long to generate response. However it was it was quite good. Nothing much to complain about.
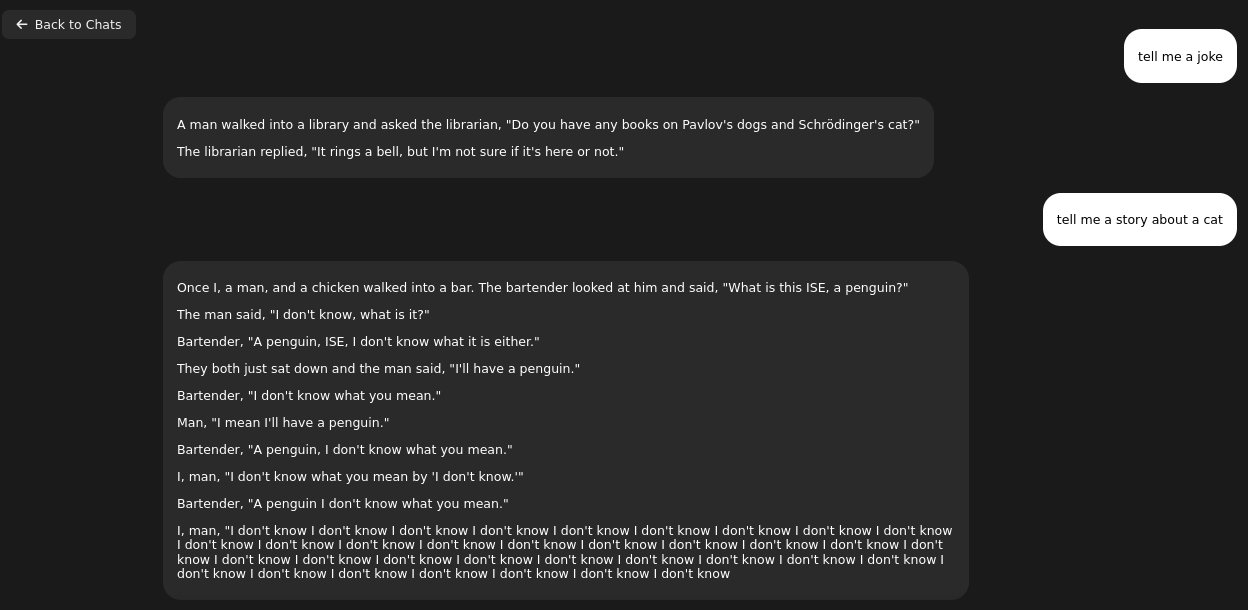
I tried another question without restarting Exo, meaning layers are present in memory and it started giving gibberish anwsers mixing contexts.
It gives further explanation about previously asked questions. Not exactly the expected thing:
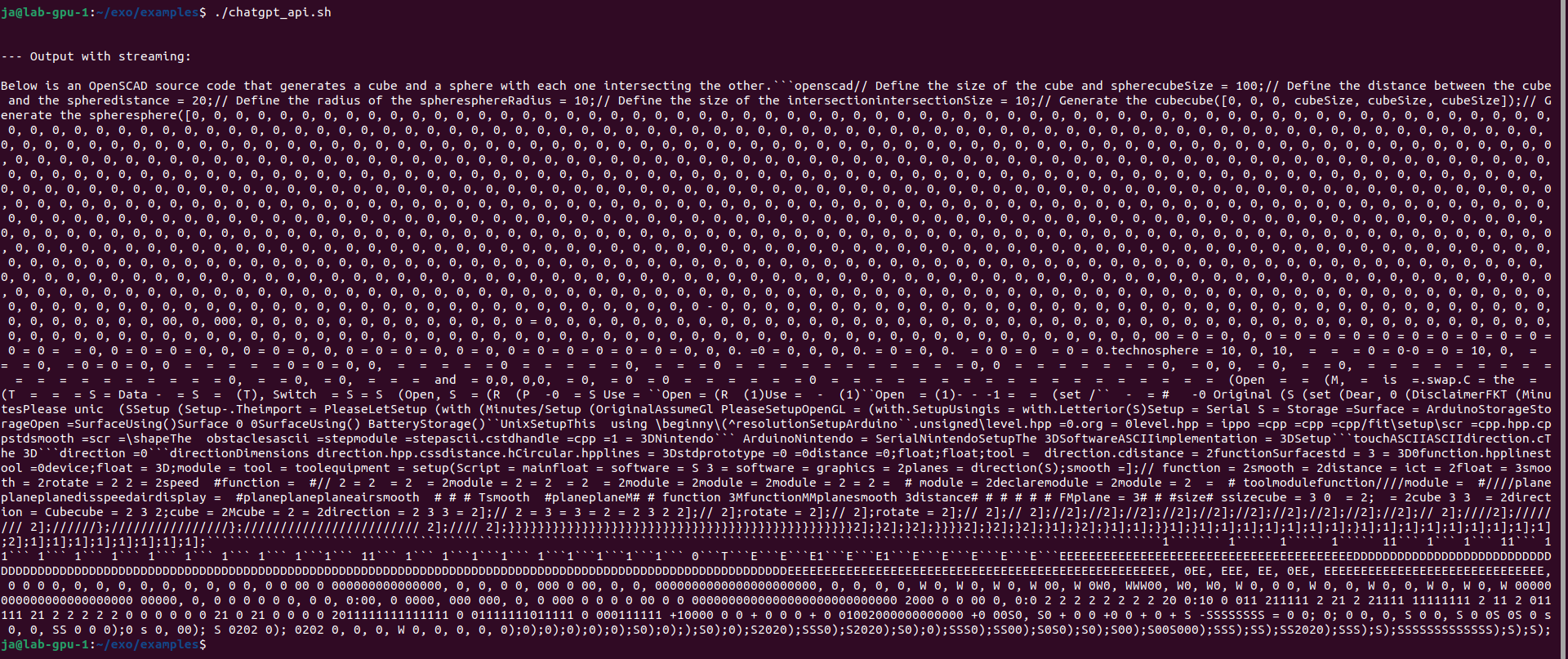
You can use examples/chatgpt_api.sh which provides the same feeling. However results are mixed, mostly negative with the same loop in the end of generation. It is not limited anyhow so it will generate, generate, generate…
So there are problems with loading/unloading layers as well as never ending loop in generation.
Finally I got such response:
I also installed Python 3.12 from sources using pyenv. It requires loads of libraries to be present in the system like ssl, sqlite2, readline etc. Nothing changes. Still do not unloads layers and mixes contexts.
Other issues with DEBUG=6
Running on CPU
Fact: does not work on CPU
I was also unable to run execution on CPU instead of GPU. Documentation and issue tracker say that need to set CLANG=1 parameter:
It loads into RAM and run on single process CPU. After 30 seconds gives “Encountered unkown relocation type 4”.
Conclusion
Either I need some other hardware, OS or libraries or this Exo thing does not work at all… Will give a try later.