Quick overview of LLM MLX LORA training parameters.
weight_decay
A regularization technique that adds a small penalty to the weights during training to prevent them from growing too large, helping to reduce overfitting. Often implemented as L2 regularization.examples: 0.00001 – 0.01
grad_clip
Short for gradient clipping — a method that limits (clips) the size of gradients during backpropagation to prevent exploding gradients and stabilize training.examples: 0.1 – 1.0
rank
Refers to the dimensionality or the number of independent directions in a matrix or tensor. In low-rank models, it controls how much the model compresses or approximates the original data.examples: 4, 8, 16 or 32
scale
A multiplier or factor used to adjust the magnitude of values — for example, scaling activations, gradients, or learning rates to maintain numerical stability or normalize features.examples: 0.5 – 2.0
dropout
A regularization method that randomly “drops out” (sets to zero) a fraction of neurons during training, forcing the network to learn more robust and generalizable patterns.examples: 0.1 – 0.5
Full fine-tuning of mlx-community/Qwen2.5-3B-Instruct-bf16
Recently I posted article on how to train LORA MLX LLM here. Then I asked myself how can I export or convert such MLX model into HF or GGUF format. Even that MLX has such option to export MLX into GGUF most of the time it is not supported by models I have been using. From what I recall even if it does support Qwen it is not version 3 but version 2 and quality suffers by such conversion. Do not know why exactly it works like that.
So I decided to give a try with full fine-tuning using transformers, torch and accelerate.
Input data
In terms of input data we can use the same format as with LORA MLX LLM training. So there are two kind of files which is train.jsonl and valid.jsonl with the following format:
{"prompt":"This is the question", "completion":"This is the answer"}
Remember that this is full training, not only low rank adapters. So it is a little bit harder to get proper results. It is crucial to get as much good quality data as possible. I take source documents and run augumentation process using Langflow.
Full fine-tuning program
Next there is source code for training program code. You can see that you need transformers, accelerate, PyTorch and Datasets. The first and the only parameter is output folder for weights. After the training is done there are some test questions to be asked in order to verify quality of trained model.
Within 4 epochs and size of 2 batches at a time but accumulated with 12x factor we have been learning at the speed of 5e-5. Our warmup takes 10% of runtime. We run cosine decay with certain weight_decay and gradients normalization. We try to use BF16, do not use FP16 but your milage may vary. Logging take place at every 10 steps (for training loss). We eval every 50 steps (for validation loss). However we save every 100 steps. We save best checkpoint in the end and 2 checkpoints at maximum.
HF to GGUF conversion
After training finished we convert this HF format into GGUF in order to run it using LMStudio.
# get github.com/ggml-org/llama.cpp.git
# initialize venv and install libraries
python convert_hf_to_gguf.py ../rt/model/checkpoint-x/ --outfile ../rt/model/checkpoint-x-gguf
However it is recommended only do this after test questions gives any good results. Otherwise it will be pointless.
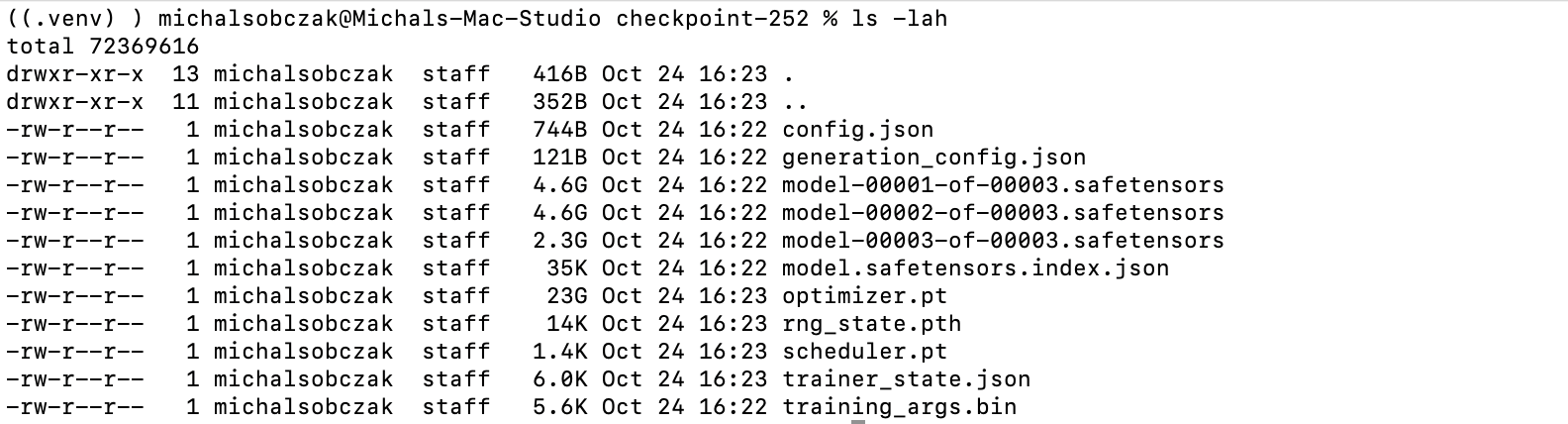
If after test questions we would decide that current weights are capable then we can conver HF format into GGUF two checkpoints, checkpoint-200 and checkpoint-252 as well as some other files like vocab and tokenizer:
Judge the quality yourself, especially comparing to LORA trainings. In my personal opinion full fine-tuning requires much higher level of expertise than just training a subset of full model.
I have done over 500 training sessions using Qwen2.5, Qwen3, Gemma and plenty other LLM publicly available to inject domain specific knowledge into the model’s low rank adapters (LORA). However, instead of giving you tons of unimportant facts I will just stick to the most important things. Starting with the fact that I have used MLX on my Mac Studio M2 Ultra as well as on MacBook Pro M1 Pro. Both fit well to this task in terms of BF16 speed as well as unified memory capacity and speed (up to 800GB/s).
Memory speed is the most important factor comparing GPU hardware withing similar generations of technological process. That is why M2/M3 Ultra with higher memory speeds beats M4 with lower overall memory bandwidth.
LORA and MLX
What is LORA? With this type of training you take only portion of large model and train only small part of parameters, like 0.5 or 1%, which in most of models gives us 100k up to 50M parameters available for training. What is MLX? it is Apple’s array computation framework which boosts machine learning tasks.
How MLX and LORA relates to different frameworks on different hardware? MLX uses slightly different weights organization and different way of achieving the same thing as other frameworks do, but with Apple Silicon speed-up. It is pricey in terms of purchase and power consumption to run modern powerful NVIDIA RTX based training, and it is much more affordable to do this on Mac Studio with lets say 64GB of RAM. Please notice that for ML (GPU related things generally speaking) tasks you get like 75% of your RAM capacity, so on 64GB Mac Studio I get around 45 – 46GB available. Now go online and look for some RTXs with similar amount of VRAM 😉
Configuration
So…
Here you have sample training configuration using Qwen2.5 rather big model which is 14B, pre-trained for Instruct type usage, storing weights in BF16 which is faster to run up to 50% than similar 16 bit floats or even 8 bits weights. I got “only” 64GB and 32GB of memory respectively so I use lower batch_size and higher gradient_accumulation which effectively gives me 4 x 8 batch size.
The most important parameters in terms of training are:
number of layers which relates to the number of parameters available for training
weight_decay in terms of generalization
grad_clip is where we defined how small/big is a hole by which we pull gradients, in order to not let them explode which means going higher and higher by sudden
learning_rate is how fast we order model to be trained with our data
lora_parameters/keys we either stick only to self_attn.* or we extend training to cover also mlp.*
rank is to define space to the training
scale also called alpha is the influence factor
dropout is a random removal/correction factor
Now, at different points/phases of training those parameters should and will take different values depending on our use case. Every parameters is somehow related to the other. Like for example learning rate correlates indirectly with WD, GC, rank, scale and d/o. If you change number of layers or rank then you need to adjust the other parameters also. Key factors for changing your parameters:
number of QA in datasets
number of training data vs validation data
data structure and quality
model parameters size
number of iterations/epochs (how many times model sees your data in training)
where you want to either generalize or specialize your data and model interaction
Training
You can run training as follows including W&B reporting for better analysis.
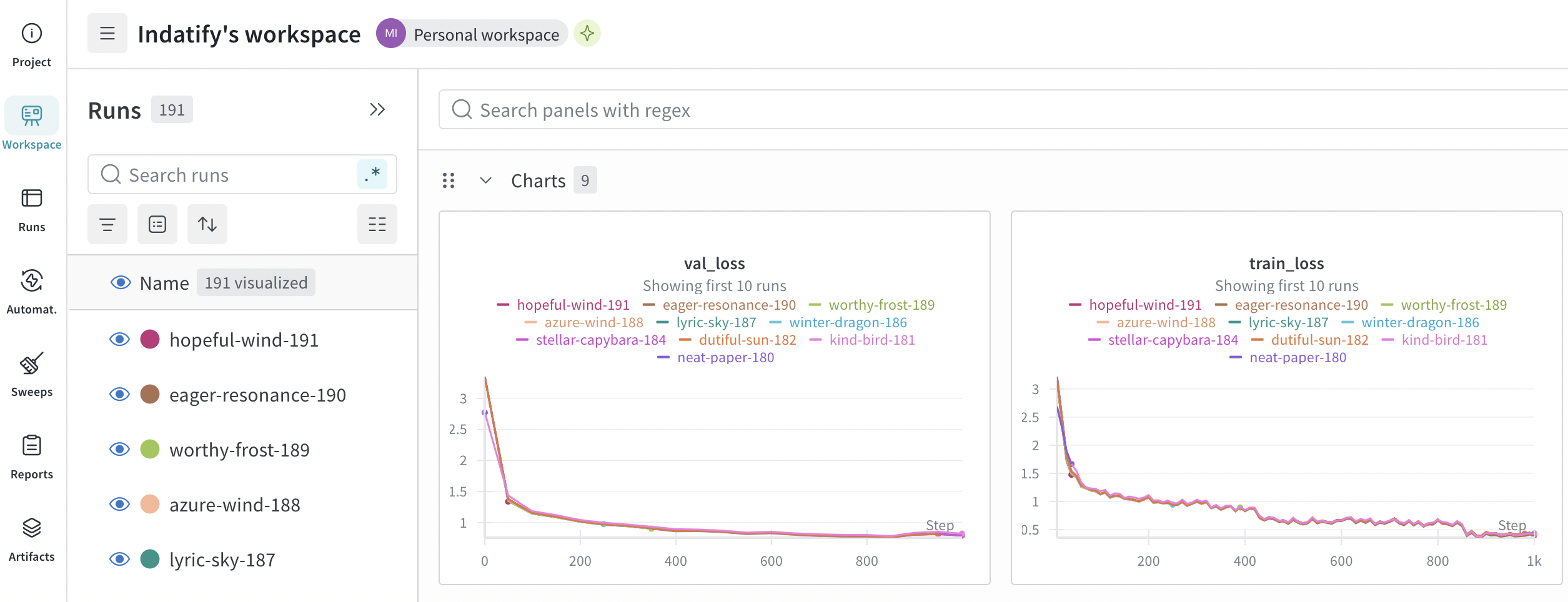
You can monitor your training either in console or oin W&B. Rule of a thumb is that validation loss should go down and should go down together with training loss. Training loss should not be much lower than validation loss which could mean overfitting data which degrades model’s ability to generalize things. Ideal configuratino is go as low as possible, both both validation and training loss.
Iter 850: Val loss 0.757, Val took 99.444s
Iter 850: Train loss 0.564, Learning Rate 1.065e-05, It/sec 0.255, Tokens/sec 177.088, Trained Tokens 581033, Peak mem 33.410 GB
Iter 850: Saved adapter weights to adapters-drs2/adapters.safetensors and adapters-drs2/0000850_adapters.safetensors.
...
Iter 900: Val loss 0.805, Val took 99.701s
Iter 900: Train loss 0.422, Learning Rate 8.303e-06, It/sec 0.248, Tokens/sec 173.218, Trained Tokens 615120, Peak mem 33.410 GB
Iter 900: Saved adapter weights to adapters-drs2/adapters.safetensors and adapters-drs2/0000900_adapters.safetensors.
...
Iter 1000: Val loss 0.791, Val took 99.140s
Iter 1000: Train loss 0.396, Learning Rate 4.407e-06, It/sec 0.248, Tokens/sec 172.078, Trained Tokens 683991, Peak mem 33.410 GB
Iter 1000: Saved adapter weights to adapters-drs2/adapters.safetensors and adapters-drs2/0001000_adapters.safetensors.
Saved final weights to adapters-drs2/adapters.safetensors.
Fusing LORA and exporting GGUF
Once you are ready and done with your traing you can either use LORA adapter in generation of just fuse this LORA adapter it into base model which is more handy as it can be also copied into LMStudio model directory for much more user friendly use and your newly trained model evaluation.
Where $1 is HuggingFace base model path, $2 is model name in output path. You can also fuse into GGUF format by using --export-gguf and you can also convert HF model into GGUF using llama.cpp (https://github.com/ggml-org/llama.cpp.git). Please note that converting it into GGUF or converting it into Ollama “format” will possibly cause quality issues. Cause for this might be because of weights formatting, number representation or other graph difrerences which are by now not idientifed on my side.
You need data to start training. It is whole separate concept aside from properly parametrizing your training process. It is not only data itself but whole augumentation process including paraphrases, synonyms, negative examples, step-by-step etc.
Available formats are as follows:
{"messages": [{"role": "user", "content": "What is AI?"}, {"role": "assistant", "content": "AI is..."}]}
{"prompt": "Explain quantum computing", "completion": "Quantum computing uses..."}
{"text": "Complete text for language modeling"}
Tried all of them and the most applealing seems to be prompt/completion one.
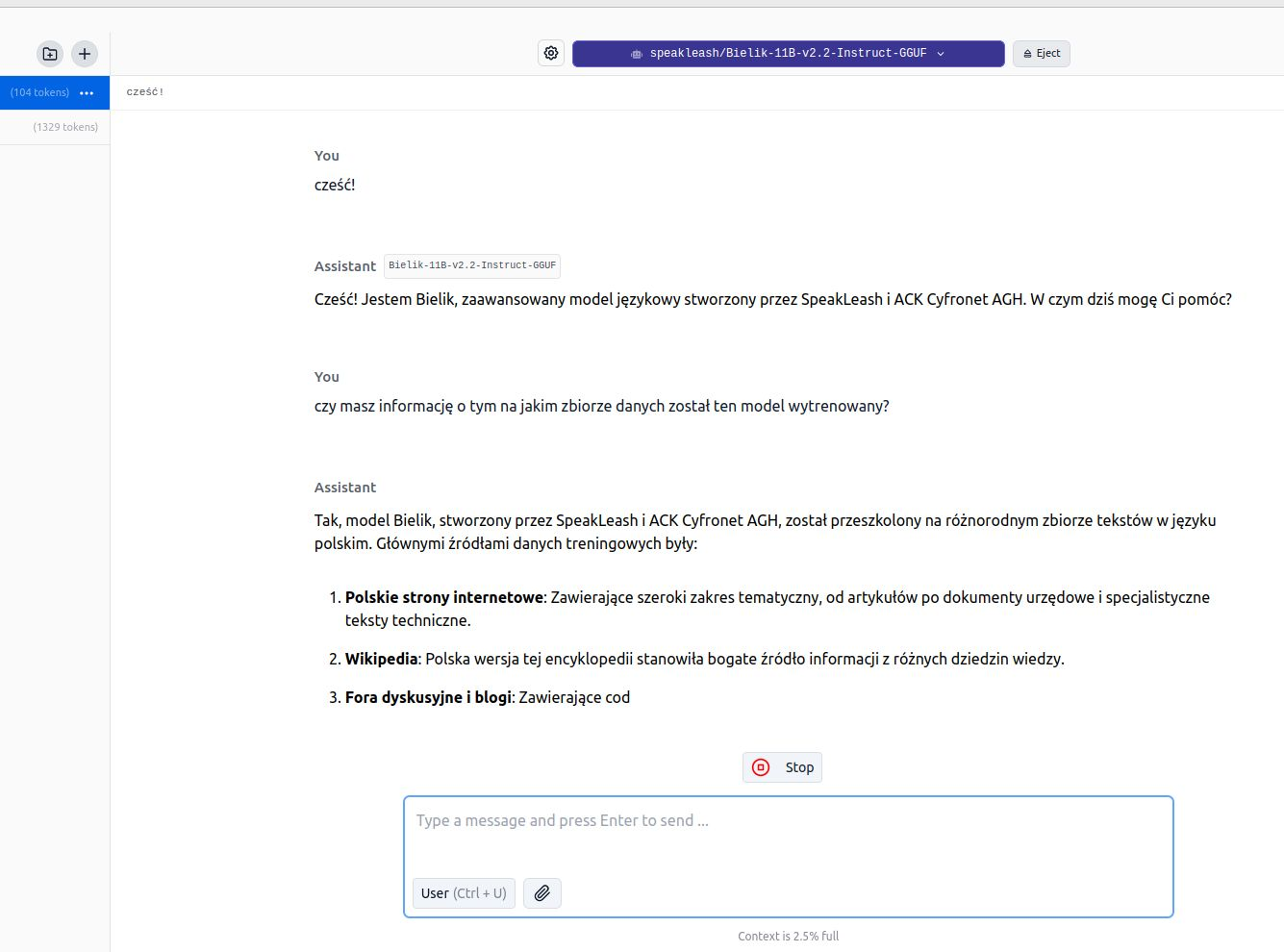
Did you know that you can use the Polish LLM Bielik from SpeakLeash locally, on your private computer? The easiest way to do this is LM Studio (from lmstudio.ai).
download LM Studio
download the model (e.g. Bielik-11B-v2.2-Instruct-GGUF)
load model
open a new conversation
converse…
Why use a model locally? Just for fun. Where we don’t have internet. Because we don’t want to share our data and conversations etc…
You can run it on macOS, Windows and Linux. It requires support for AVX2 CPU instructions, a large amount of RAM and, preferably, a dedicated and modern graphics card.
Note: for example, on a Thinkpad t460p with i5 6300HQ with a dedicated 940MX 2GB VRAM card basically does not want to work, but on a Dell g15 with i5 10200h and RTX 3050Ti it works without any problem. I suspect that it is about Compute Capability and not the size of VRAM in the graphics card… because on my old datacenter cards (Tesla, Quadro) these models and libraries do not work.
Did you know that you may block AI-related web-scrapers from downloading your whole websites and actually stealing your content. This way LLM models will need to have different data source for learning process!
Why you may ask? First of all, AI companies make money on their LLM, so using your content without paying you is just stealing. It applies for texts, images and sounds. It is intellectual property which has certain value. Long time ago I placed on my website a license “Attribution-NonCommercial-NoDerivatives” and guest what… it does not matter. I did not receive any attribution. Dozens of various bot visit my webiste and just download all the content. So I decided…
… to block those AI-related web-crawling web-scraping bots. And no, not by modyfing robots.txt file (or any XML sitemaps) as it might be not sufficient in case of some chinese bots as they just “don’t give a damn”. Neither I decided to use any kind of plugins or server extenstions. I decided to go hard way:
And decide to which exactly HTTP User Agent (client “browser” in other words) I would like to show middle finger. For those who do not stare at server logs at least few minutes a day, “Bytespider” is a scraping-bot from ByteDance company which owns TikTok. It is said that this bot could possible download content to feed some chinese LLM. Chinese or US it actually does not matter. If you would like to use my content, either pay me or attribute usage of my content. How you may ask? To be honest I do not know.
There is either hard way (as with NGINX blocking certain UA) or diplomacy way which could lead to creating a websites catalogue which do not want to participate in AI feeding process for free. I think there are many more content creators who would like to get some piece of AI birthday cake…
Asking BLOOM-560M “what is love?” it replies with “The woman who had my first kiss in my life had no idea that I was a man”. wtf?!
Intro
I’ve been into parallel computing since 2021, playing with OpenCL (you can read about it here), looking for maximizing devices capabilities. I’ve got pretty decent in-depth knowledge about how computational process works on GPUs and I’m curious how the most recent AI/ML/LLM technology works. And here you have my little introduction to LLM topic from practical point-of-view.
Course of Action
BLOOM overview
vLLM
Transformers
Microsoft Azure NV VM
What’s next?
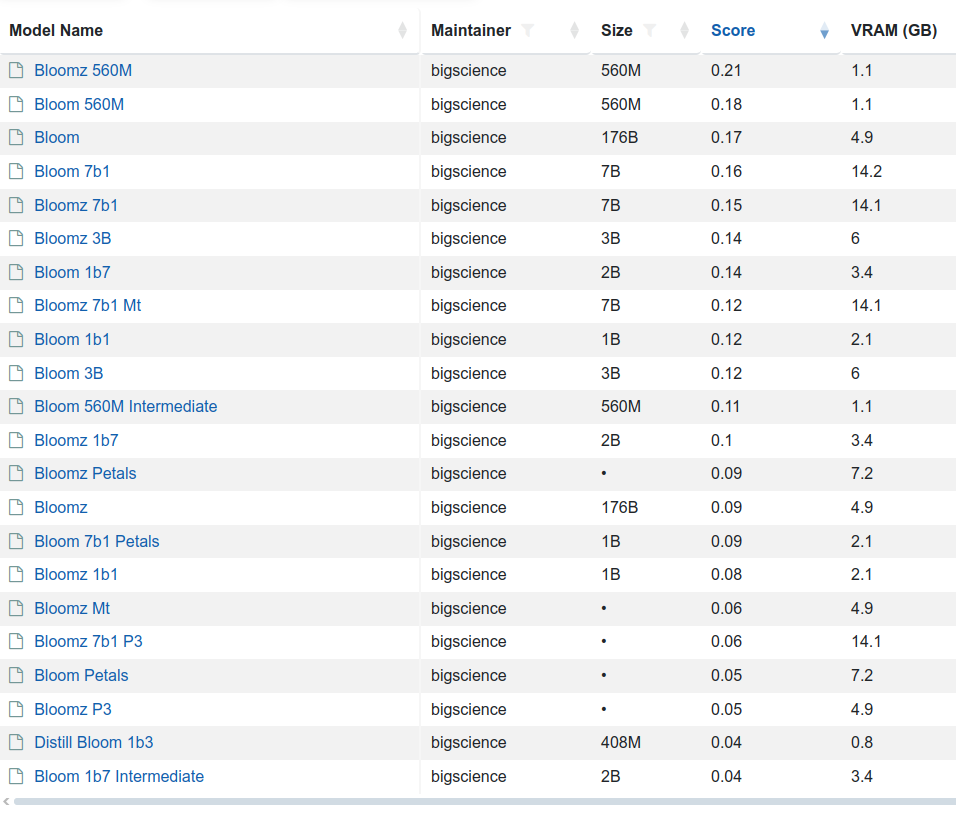
What is BLOOM?
It is a BigScience Large Open-science Open-access Multilingual language model. It based on transformer deep-learning concept, where text is coverted into tokens and then vectors for lookup tables. Deep learning itself is a machine learning method based on neural networks where you train artificial neurons. BLOOM is free and it was created by over 1000 researches. It has been trained on about 1.6 TB of pre-processed multilingual text.
There are few variants of this model 176 billion elements (called just BLOOM) but also BLOOM 1b7 with 1.7 billion elements. There is even BLOOM 560M:
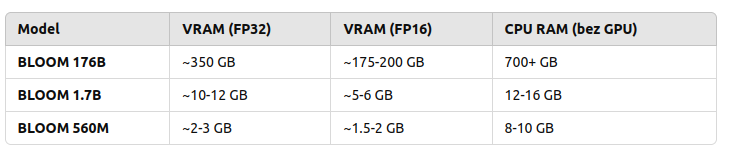
to load and run 176B you need to have 350 GB VRAM with FP32 and half with FP16
to load and run 1B7 you need somewhere between 10 and 12 GB VRAD and half with FP16
So in order to use my NVIDIA GeForce RTX 3050 Ti with 4GB RAM I would either need to run with BLOOM 560M which requires 2 to 3 GB VRAM and even below 2 GB VRAD in case of using FP16 mixed precision or… use CPU. So 176B requires 700 GB RAM, 1B7 requires 12 – 16 GB RAM and 560M requires 8 – 10 GB RAM.
Are those solid numbers? Lets find out!
vLLM
“vLLM is a Python library that also contains pre-compiled C++ and CUDA (12.1) binaries.”
“A high-throughput and memory-efficient inference and serving engine for LLMs”
You can download (from Hugging Face, company created in 2016 in USA) and serve language models with these few steps:
pip install vllm
vllm serve "bigscience/bloom"
And then once it’s started (and to be honest it won’t start just like that…):
You can back up your vLLM runtime using GPU or CPU but also ROCm, OpenVINO, Neuron, TPU and XPU. It requires GPU compute capability 7.0 or higher. I’ve got my RTX 3050 Ti which has 8.6, but my Tesla K20Xm with 6GB VRAD has only 3.5 so it will not be able to use it.
[rank0]: torch.OutOfMemoryError: CUDA out of memory. Tried to allocate 736.00 MiB. GPU 0 has a total capacity of 3.81 GiB of which 73.00 MiB is free. Including non-PyTorch memory, this process has 3.73 GiB memory in use. Of the allocated memory 3.56 GiB is allocated by PyTorch, and 69.88 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management (https://pytorch.org/docs/stable/notes/cuda.html#environment-variables)
or the following:
No available memory for the cache blocks. Try increasing `gpu_memory_utilization` when initializing the engine.
I may try later to check it out on bigger GPU but as for now, I will try to run it using transformers library which is the next topic.
Transformers
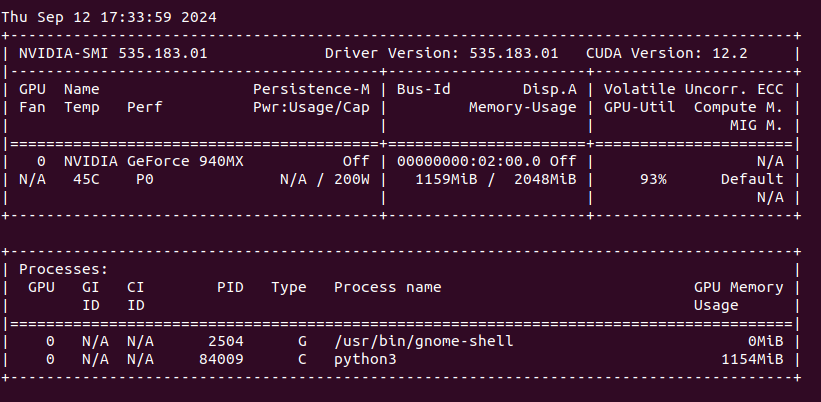
So I picked the same BLOOM 560M model. First, you need to install the following main packages and plenty of dependencies:
It will download the model and execute in Python program.
We can see that my NVIDIA GeForce 940MX with 2 GB VRAM is loaded around 60% with over 90% utilization (results from nvidia-smi).
“What is love?”. Anwser is as follows:
What is love? She never asked me the question but I am the one who has to give my answer. She is a beautiful, beautiful, very beautiful woman. The first thing you know about love is that it is the most complicated thing in the world. I was so shocked when I saw the man I thought I was marrying. My life was over. The woman who had my first kiss in my life had no idea that I was a man. She was so shocked. She said something
Next I asked for “The sun is shining and?”
I love this scene and I like when it comes to it. The sun, the sky and all the other stars are bright and I love that! I really enjoy this scene and it sets the scene for the rest of the story. It seems like the characters are just going about their day and the sun is shining. The world seems to be in its perfect place and everything is beautiful. I love the lighting in this scene and the warmth of the sunlight that
Does it make any sense? What is a concept of “sense” at all? Anyway it works, somehow. Lets find out the other possibilities.
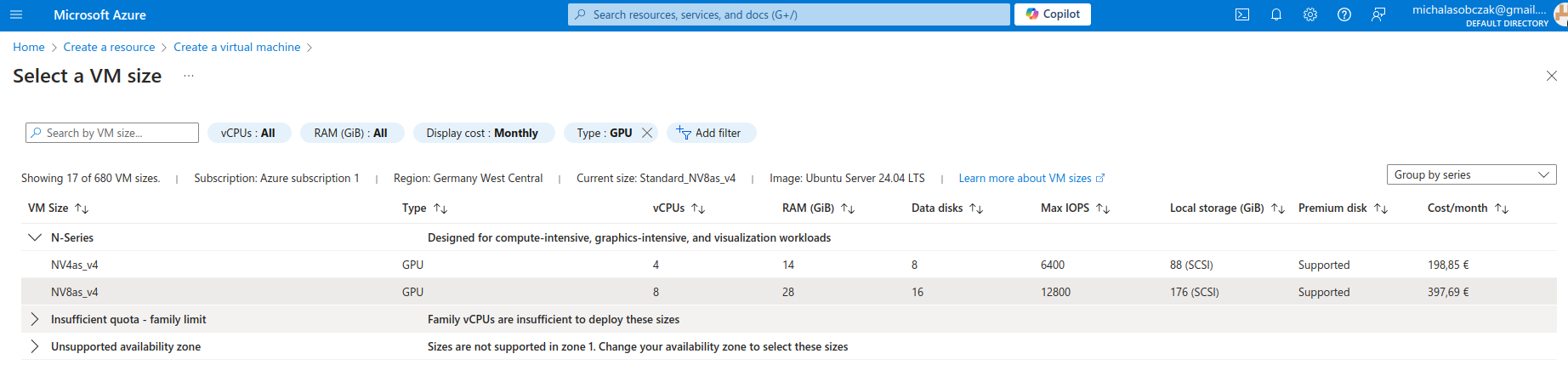
Microsoft Azure N-series virtual machines
Instead of buying MSI Vector, ASUS ROG, Lenovo Legion Pro, MSI Raider or any kind of ultimate gaming laptops you go to Azure and pick on their NV virtual machines. Especially that they have 14 and 28 GB of VRAM onboard. It costs around 400 Euro per month, but you will not be using it all the time (I suppose).
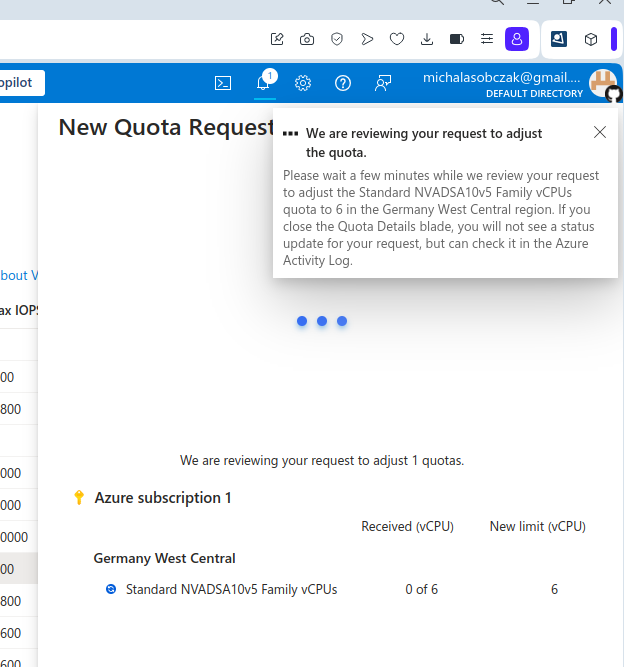
And I was not so sure how to use AMD GPU, so instead I decided to requests for a quote increase:
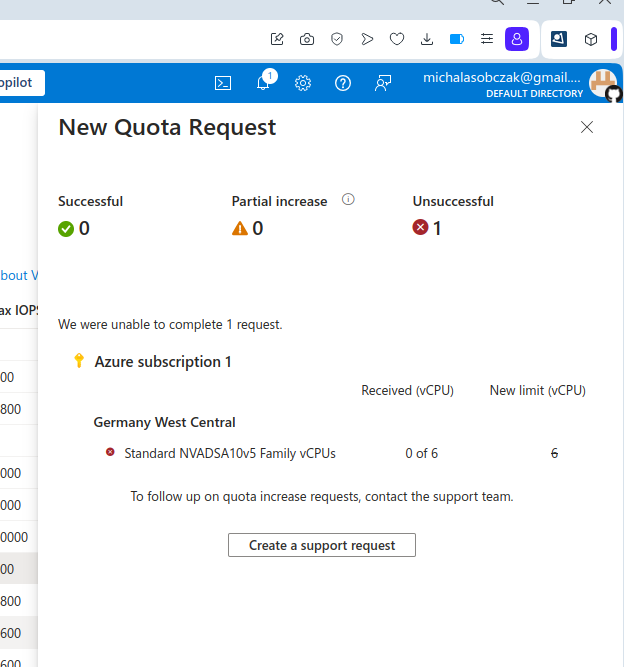
However I got rejected on my account with that request:
Unfortantely changing parameters and virtual machine types did not change the situation, I got still rejected and neeeded to submit support ticket to Microsoft in order to manually process it. So until next time!