I thought that the best option to run Frigate is to run bare metal and skip virtualization and system containers. However now situation changed a little bit as I was able to fire up Frigate on LXC container on Proxmox with little help of AMD ROCm hardware assisted video decryption.
And yes, detection crashes on ONNX and need to run on CPU instead… but video decryption works well. And even more, detection on 16 x AMD Ryzen 7 255 w/ Radeon 780M Graphics (1 Socket) works very well for almost 20 video streams (mixed H264 and H265). You can switch to Google Coral as USB device passed to the LXC container, but what for?
LXC container
You need to have the following settings:
/dev/dri/renderD128
fuse
mknod
nesting
privileged
ROCm installation
https://rocm.docs.amd.com/projects/install-on-linux/en/latest/install/quick-start.html
wget https://repo.radeon.com/amdgpu-install/7.1.1/ubuntu/noble/amdgpu-install_7.1.1.70101-1_all.deb
sudo apt install ./amdgpu-install_7.1.1.70101-1_all.deb
sudo apt update
sudo apt install python3-setuptools python3-wheel
sudo usermod -a -G render,video $LOGNAME # Add the current user to the render and video groups
sudo apt install rocm
YOLOX is an anchor-free version of YOLO, with a simpler design but better performance! It aims to bridge the gap between research and industrial communities. For more details, please refer to our report on Arxiv.
No, cant use Tesla K20xm with 6GB VRAM for modern computation as it has Compute Capability parameter lower than required 7.0. Here you have table of my findings about libraries/frameworks, required hardware and its purpose.
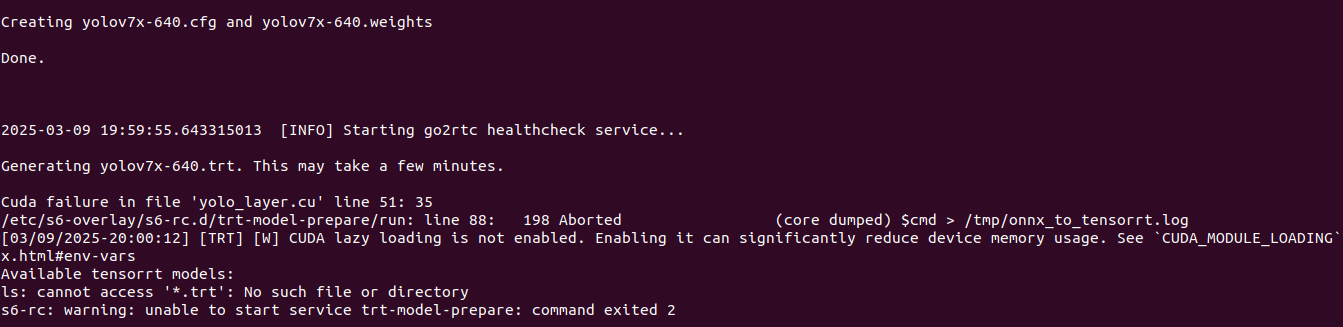
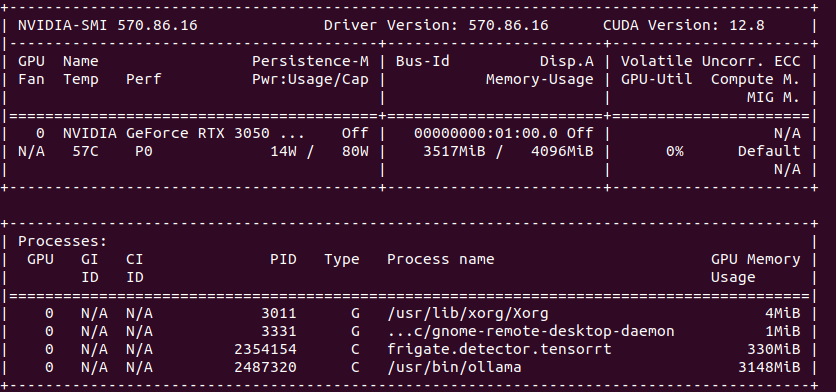
I started with DeepStack, where I was able to run API server for object detection, Frigate has support for it. Later on, with TensorRT on NVIDIA GPU I can run Yolov7x-640 model also for object detection, Frigate works well with it. With Google Coral TPU USB module we can run SSD MobileNet or EfficientDet models with great power efficency for good price. Ollama with moondream is both general purpose and computer vision description if run with moondream model, works great with Frigate for scene outlook. Last thing I tried is OpenVINO which enables Intel devices for object detection, works great with ssdlite_mobilenet_v2 model.
Library/Framework
Type
Requirement
Purpose
DeepStack
AI API server
NVIDIA CC 5.0 (3.5/3.7?)
Object detection
TensorRT
deep learning inference SDK
NVIDIA CC 5.0 (3.0/3.5?)
Object detection
Google Coral TPU
neural networks accelerator
n/a
Object detection
Ollama/moondream:1.8b
vision language model
NVIDIA CC 7.0 (5.0?)
Computer vision
Exo/Llama
pipeline parallel inference
NVIDIA CC 7.0 (5.0?)
General purpose
OpenVINO Intel iGPU + CPU
deep learning toolkit
Intel iGPU, CPU 6th gen
General purpose
ResortRT: requirements validation
It is not entirely true that TensorRT is supported by CC 3.5 as I have tested on Tesla K20xm and it gives me error. So I would rather say, that is may be supported given some special constraints and not exactly with Yolov7x-640 model generated on Frigate startup.
Exo: Linux/NVIDIA does not work at all
With Exo I have issues, no idea why it does not work on Linux/NVIDIA and gives gibberish results and being totally unstable with loads of smaller/bigger bugs. Llama running on the same OS and hardware on Ollama server works just fine. I will give it a try later, maybe on different release, hardware and some tips from Exo Labs, of how to actually run it.
My recommendation
For commodity, consumer hardware usage I recommend using OpenVINO, TensorRT which enables already present hardware. Buy Coral TPU if you lack of computational power. I do not see reason to run DeepStack as previously mentioned are available out-of-the-box.
“Open-source software toolkit for optimizing and deploying deep learning models.”
It is developed by Intel since 2018. It supports LLM, computer vision and generative AI. It runs on Windows, Linux and MacOS. As for Ubuntu, it is recommended to run on 22.04 LTS and higher. It utilizes OpenCL drivers.
In theory, libraries using OpenCL (such as OpenVINO) should be cross platform contrary to vendor-locked similar solutions like CUDA. In theory OpenVINO should then work on both Intel and AMD hardware. Internet says that is works, but as for now I need to order some additional hardware to check it out on my own.
Side note: Why CUDA/NVIDIA vendor-lock is bad? You are forced to buy hardware from single vendor, so you are prone to price increase and if whole concept would fail to are left with nothing. That is why open standards are better then closed ones.
OpenCL readings
For polish language speakers I recommend checking out my book covering OpenCL. There are also various articles which you can check out here.
Requirements
You can run OpenVINO on Intel Core Ultra series 1 and 2, Xeon 6, Atom X, Atom with SSE 4.2, various Pentium processors. By far the most important is that it runs on Intel Core gen 6 onwards. It is supported by Intel Arc GPU also, but in term of GPUs it is supported by Intel HD, UHD, Iris Pro, Iris Xe, Iris Xe Max. Especially compatibility with Core 6 gen and integrated HD, UHD graphics is the most crucial.
Intel OpenVINO documentation says also that it supports Intel Neural Processing Unit, in short NPU.
VMMX instruction set is available since 10th Intel CPU generation. AMX instruction set is available since 12th Intel CPU generation. Both VMMX and AMX highly increses speed and thruput of inference.
Run Frigate video surveillance with OpenVINO object detector
In Linux, Ubuntu 22 particularly, Intel devices are exposed thru /dev/dri devices, which are Direct Rendering Infrastructure. It is Linux framework present since 1998. The latest version DRI-3.0 comes from 2013.
We can test OpenVINO runtime/libraries and thus Intel hardware using Frigate, DRI device and Docker container. Here is Docker container specification:
It should include both detection and video decoding as we set hwaccel_args: preset-vaapi in Frigate configuration. In theory it should use both Intel and AMD VAAPI.
Automatically detected vaapi hwaccel for video decoding
Computer without discrete GPU
In case we have computer with Intel CPU with iGPU you can specify the following configuration:
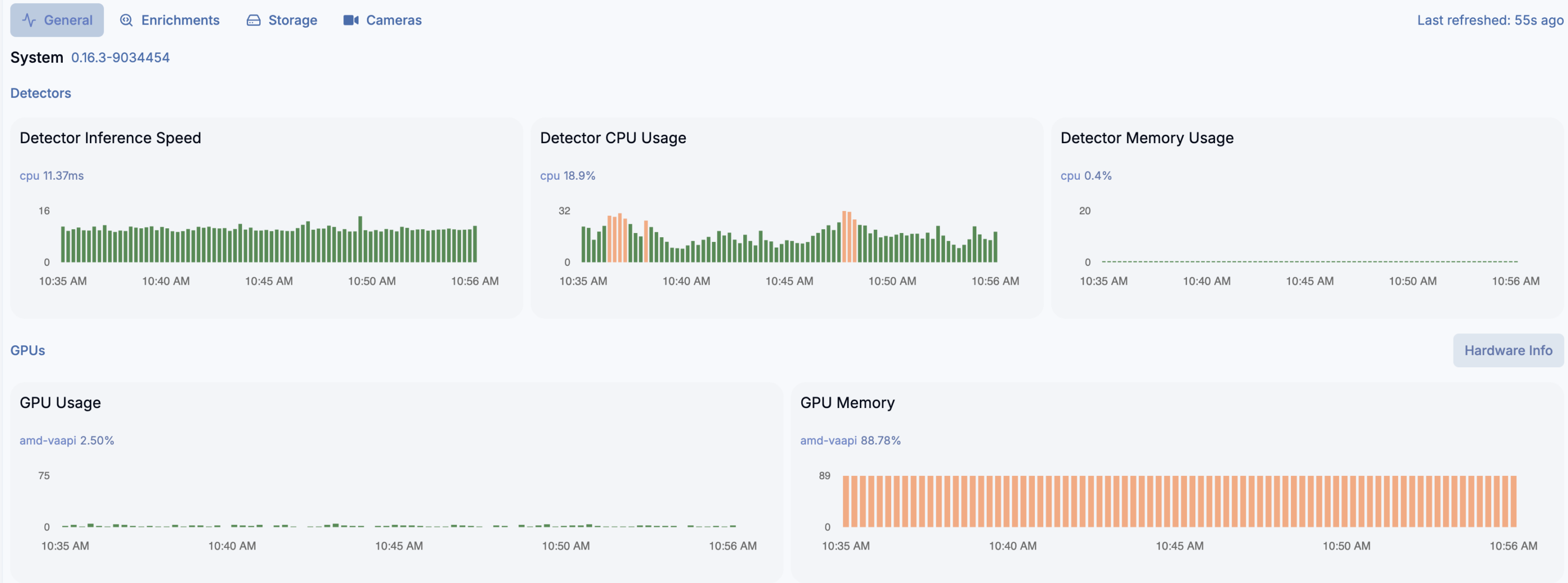
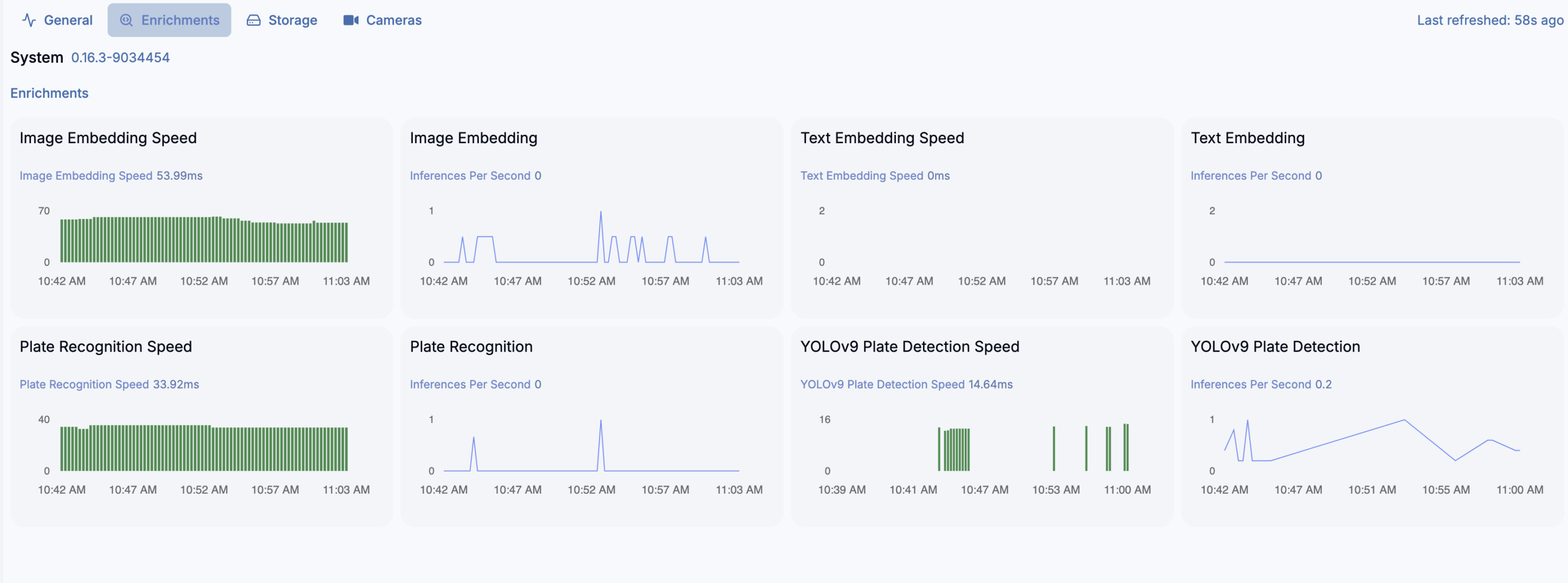
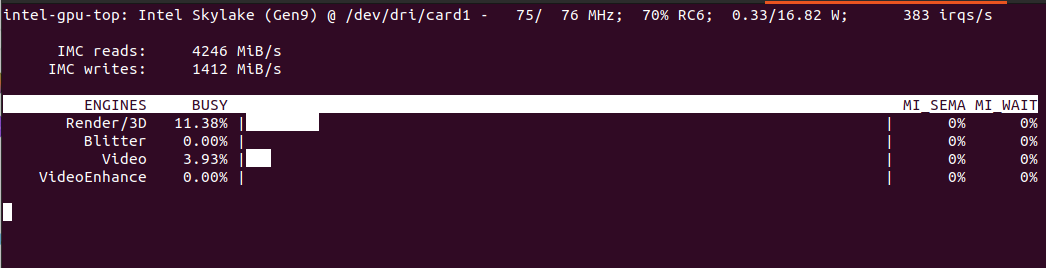
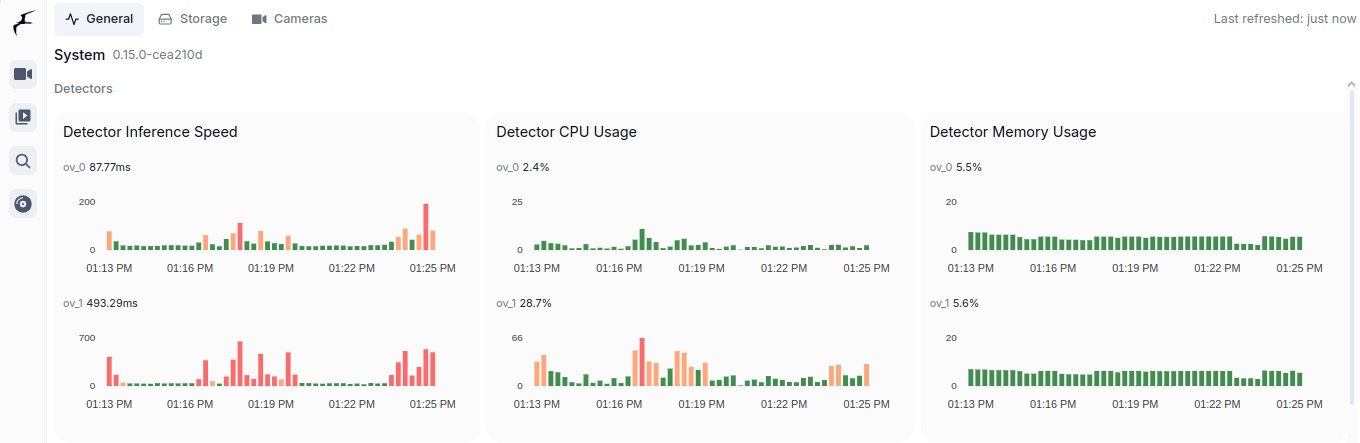
It will then use both iGPU (ov_0, fast one) and CPU (ov_1, slow one). As you can see is is interesing speed-wise (87ms vs 493ms). CPU utilization of course in case of CPU detector will be higher as CPU usage for iGPU is only for coordination. Both components show similar memory usage, which is still the RAM memory as iGPU shares it with CPU. Mine its Intel Core m3-8100y, 4 cores at 1.1GHz. It has Intel UHD 615 with 192 shader cores. It outputs 691 GFLOPS (less than 1 TFLOPS to be clear) with FP16.
You can see utilization in Frigate:
Conclusion
It is very important to utilize already available hardware and it is great thing that there is such framework like OpenVINO. There are tons of Intel Core processors with Intel HD and UHD integrated GPUs on the market. For such a use case scenario like Frigate object detection it is a perfect solution to offload detection from CPU to CPUs integrated GPU. It is much more convenient than Coral TPU USB module both in terms of installation as well as costs. You already have this GPU integrated present in your computer.
These are two majors which allow to run object detection models. Google Coral TPU is a physical module which can be in a form of USB stick. TensorRT is a feature of GPU runtime. Both allows to run detection models on them.
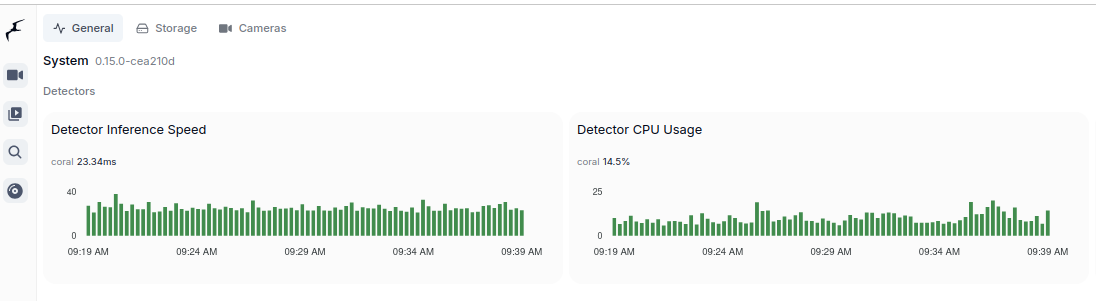
Coral TPU:
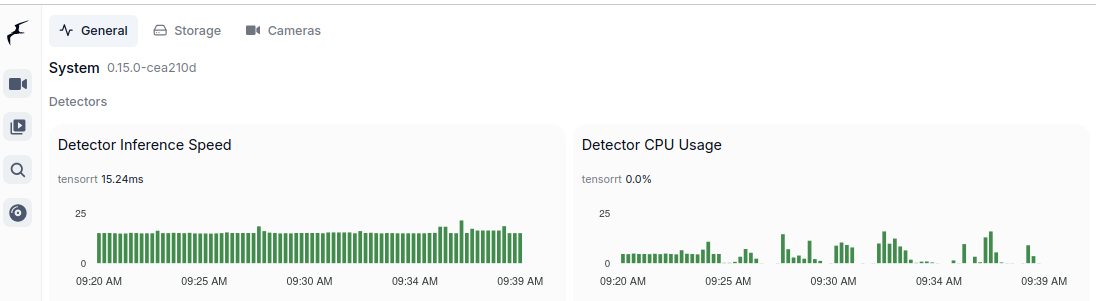
And TensorRT:
Compute Capabilities requirements
CC 5.0 is required to run DeepStack and TensorRT, but 7.0 to run Ollama moondream:1.8b. Even having GPU with CC 5.0 which is minimum required to run for instance TensorRT might be not enough due to some minor differences in implementation. It is better to run on GPU with higher CC. Moreover running on CC 5.0 means that GPU is older one which leads to performance degradation even as low as having 2 or 3 camera feeds for analysis.
Running TensorRT detection models (popular ones) requires little VRAM memory, 300 – 500 MB but it requires plenty of GPU cores and supplemental physical components to be present in such GPU, with high working clocks. In other words, you can fit those models in older GPUs but it will not perform well.
Other side of the story is to run Ollama which is GenAI requiring CC 7.0 and higher. Ollama with moondream:1.8b which is the smallest available detection model still requires little more than 3GB of VRAM.
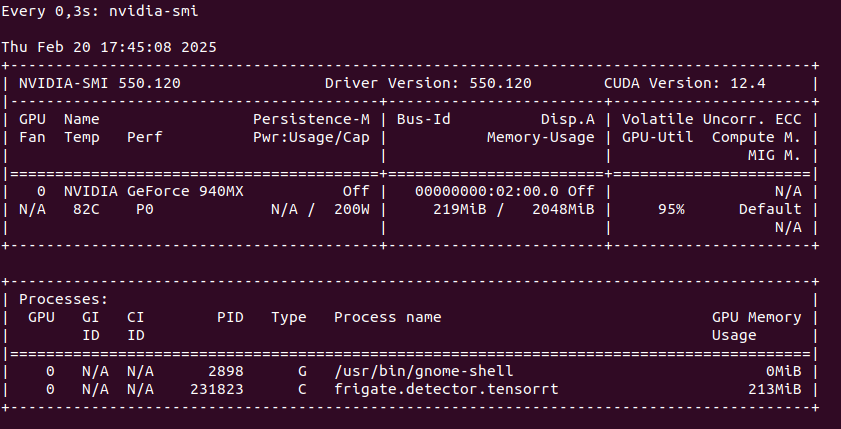
TensorRT on Geforce MX940
You can run TensorRT object detector from Frigate on NVIDIA Geforce 940MX with CC 5.0, but it will get hot at the same time you launch it. It run on driver 550 with CUDA 12.4 as follows on only one camera RTSP feed:
So this is not an option as we may burn this laptop GPU quickly. Configuration for TensorRT:
Pleas notice that Docker image is different if you want to run use GPU with TensorRT than without it. It is also not possible to run hardware accelerated decoder using FFMPEG with 940MX so disable it by passing empty array:
However if you would like to try hardware decoder with different GPU or CPU the play with this values:
preset-vaapi
present-nvidia
TensorRT on “modern” GPU
It is the best to run TensorRT on modern GPU with highest possible CC feature set. It will run detection fast, it will not get hot as quickly. Moreover it will have hardware support for video decoding. And even more you could run GenAI on the same machine.
So the minimum for object detection with GenAI descriptions is to have 4 GB VRAM. In my case it is NVIDIA RTX 3050 Ti Mobile which runs 25% at most with 4 – 5 camera feeds.
echo 'SUBSYSTEM=="usb", ATTR{idVendor}=="1a6e", GROUP="plugdev", MODE="0666"' | sudo tee /etc/udev/rules.d/99-edgetpu-accelerator.rules
sudo udevadm control --reload-rules && sudo udevadm trigger
Remember to run Coral via USB 3.0 as running it via USB 2.0 will cause performance drop by a factor of 2 or even 3 times. Second thing, to run Coral, first plug it in. Wait until it is recognized by the system:
lsusb
At first you will see not Google, but 1a6e Global Unichip. After TPU is initialized you will see 1da1 Google Inc:
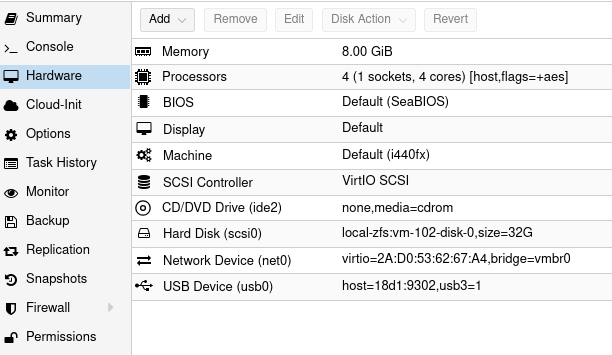
You can pass Coral TPU via Proxmox USB device, but after each Proxmox restart you need to take care of TPU initialization: