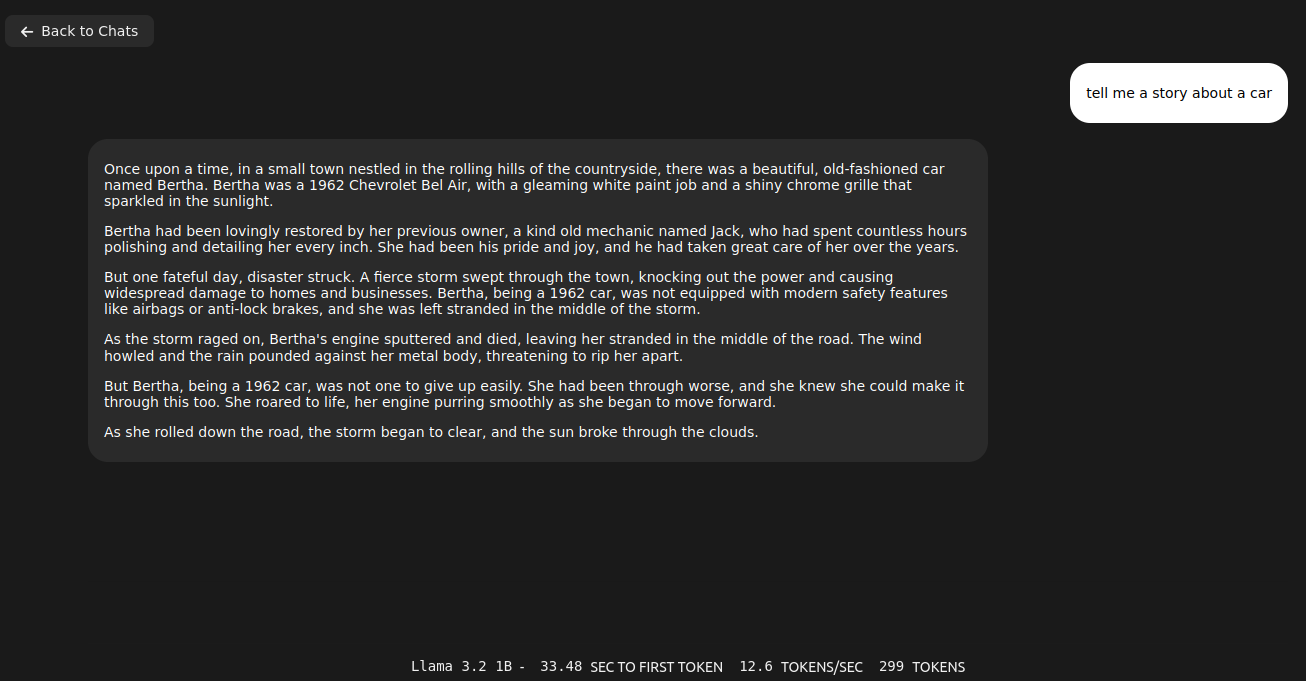
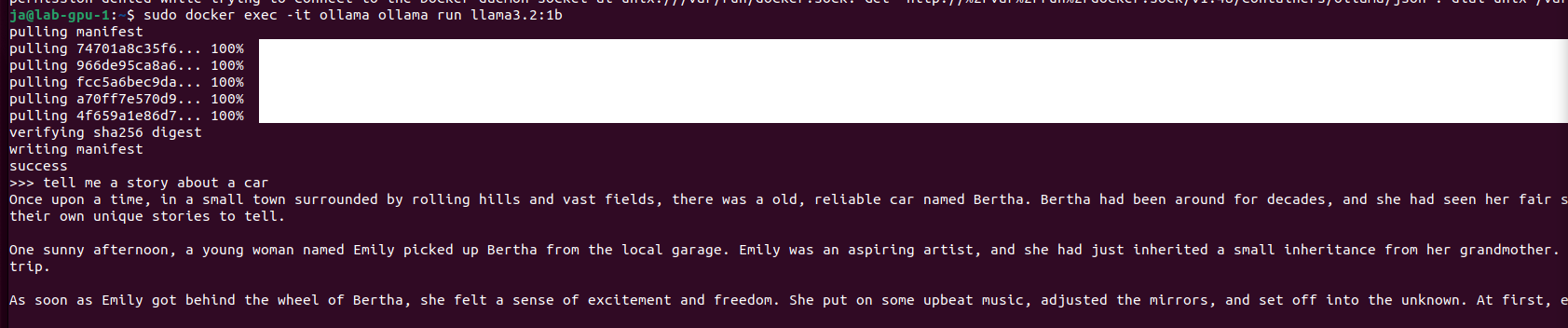
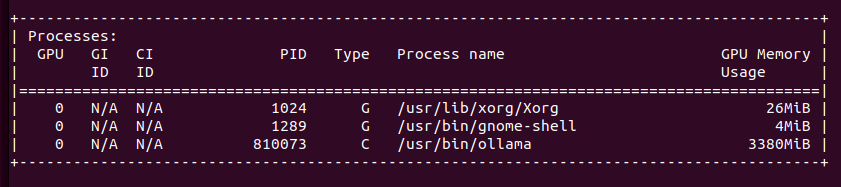
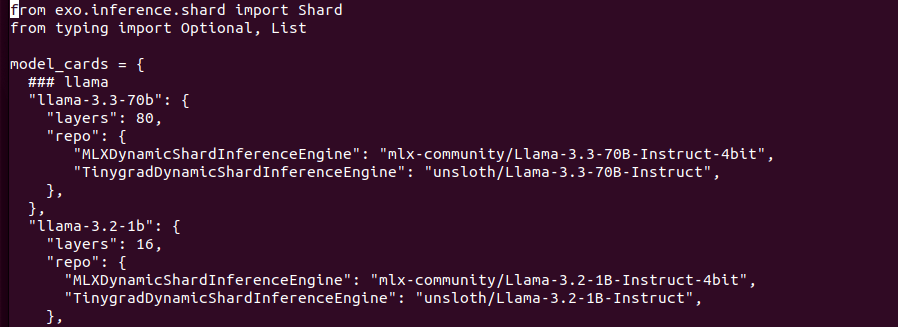
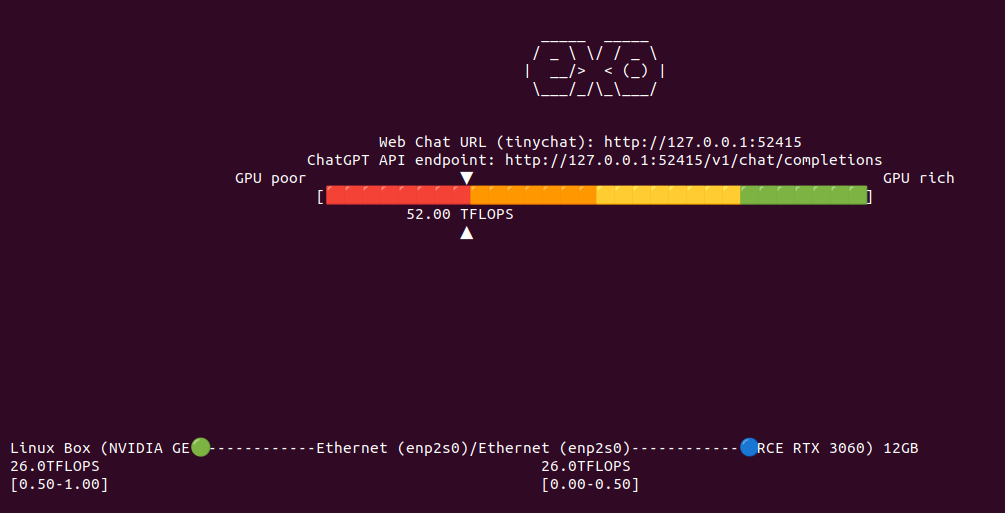
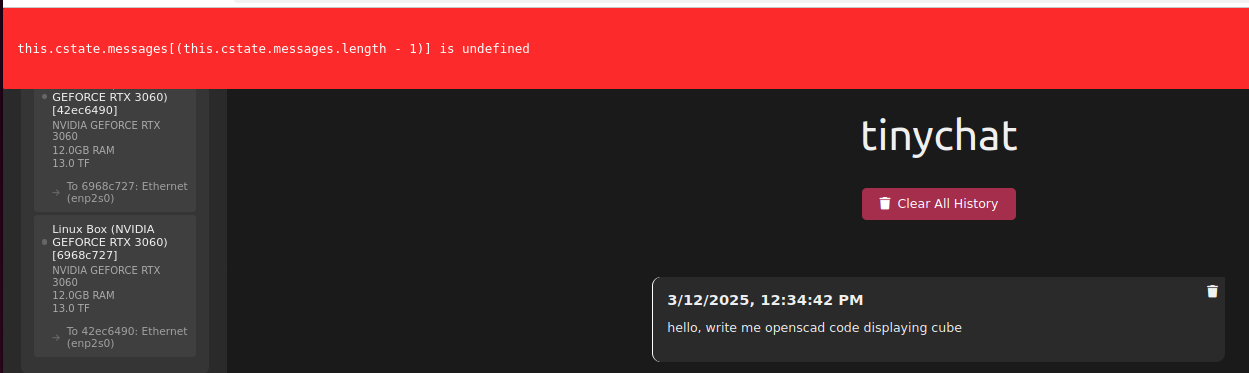
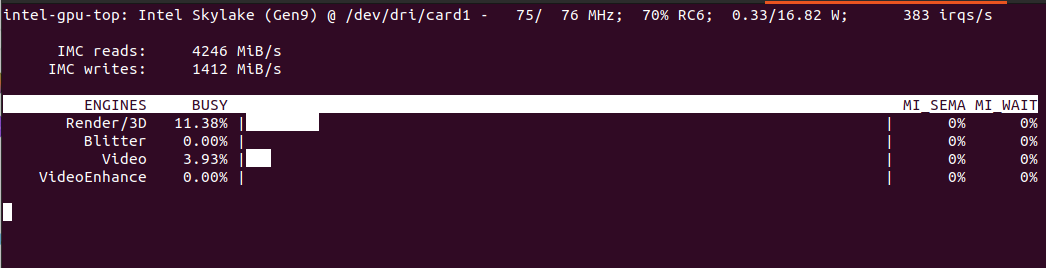
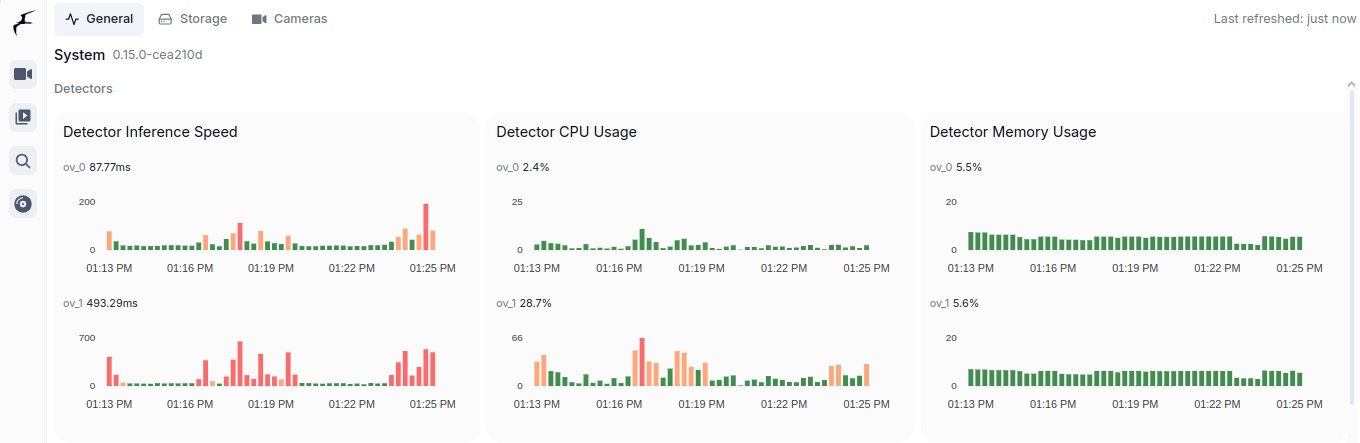
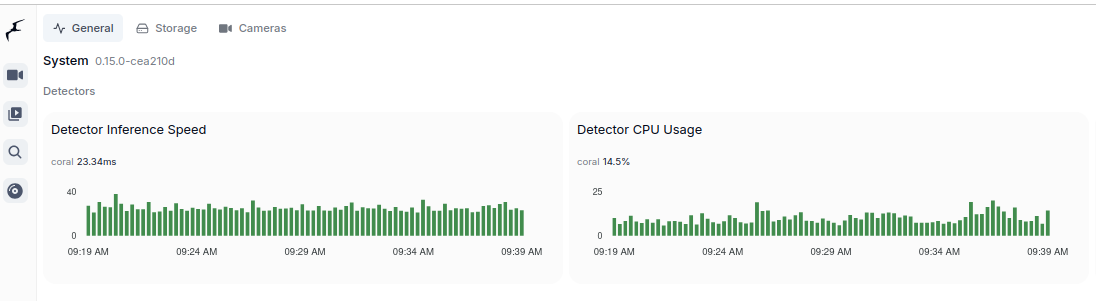
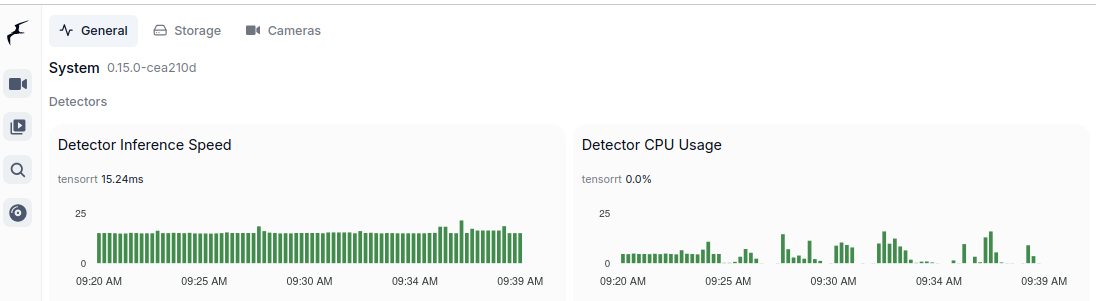
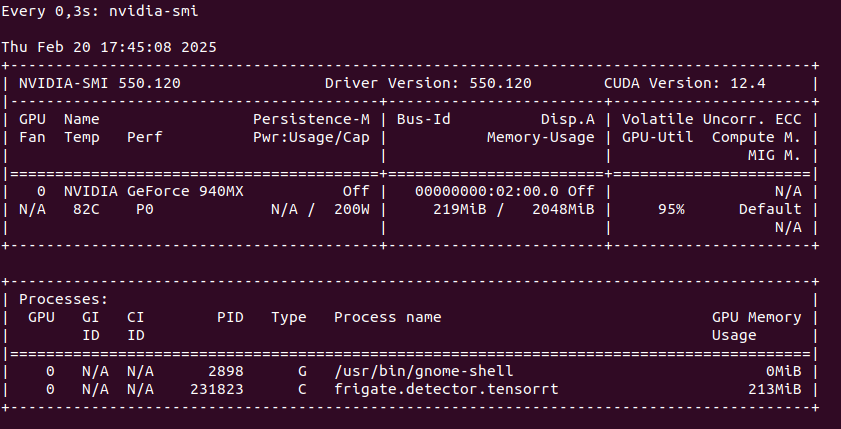
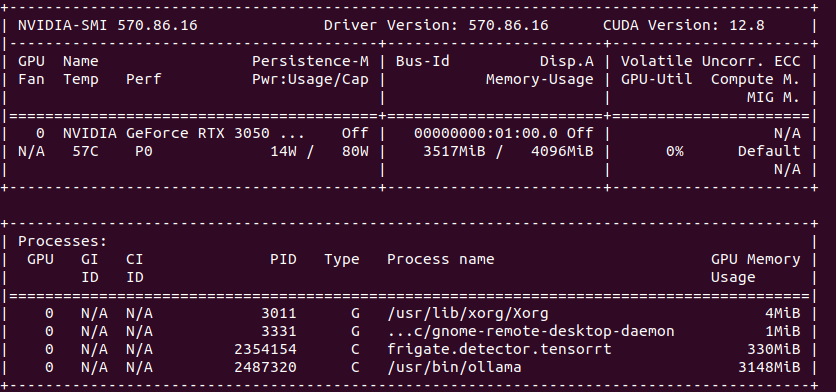
You would like to describe it using Ollama and moondream:1.8b model you can try cURL.
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:01.859560162Z","response":"\n","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:01.868641283Z","response":"The","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:01.876174776Z","response":" image","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:01.88367435Z","response":" shows","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:01.89146478Z","response":" a","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:01.899594387Z","response":" backyard","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:01.907526884Z","response":" scene","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:01.914964805Z","response":" with","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:01.922397395Z","response":" snow","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:01.929796541Z","response":" covering","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:01.937309637Z","response":" the","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:01.944999728Z","response":" ground","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:01.952626946Z","response":".","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:01.960825233Z","response":" There","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:01.968386276Z","response":" are","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:01.975957591Z","response":" two","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:01.983498832Z","response":" sets","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:01.991128609Z","response":" of","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:01.99872868Z","response":" chairs","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.006291841Z","response":" and","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.013746222Z","response":" benches","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.021306533Z","response":" in","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.028828964Z","response":" the","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.036355269Z","response":" yard","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.044167426Z","response":",","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.052942866Z","response":" one","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.061490474Z","response":" set","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.069933296Z","response":" located","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.077562662Z","response":" near","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.087034194Z","response":" the","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.094671298Z","response":" center","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.102449099Z","response":"-","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.110213167Z","response":"left","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.118013956Z","response":" side","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.125782415Z","response":" of","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.133744283Z","response":" the","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.141543102Z","response":" frame","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.149604519Z","response":" and","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.157338891Z","response":" another","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.165317974Z","response":" set","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.173592206Z","response":" situated","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.18192298Z","response":" towards","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.189629925Z","response":" the","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.197264121Z","response":" right","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.204874696Z","response":" side","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.212457215Z","response":".","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.220122564Z","response":" The","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.227777943Z","response":" chairs","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.235415009Z","response":" appear","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.243121933Z","response":" to","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.250735614Z","response":" be","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.258662805Z","response":" made","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.266973244Z","response":" of","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.27468176Z","response":" wood","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.282282895Z","response":" or","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.289846955Z","response":" metal","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.297592391Z","response":",","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.305465971Z","response":" while","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.313191208Z","response":" the","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.321349494Z","response":" benches","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.329920293Z","response":" have","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.340090732Z","response":" a","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.34802664Z","response":" similar","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.355866217Z","response":" design","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.363689099Z","response":".","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.3714811Z","response":" A","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.379121817Z","response":" p","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.3867409Z","response":"otted","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.394364121Z","response":" plant","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.402002067Z","response":" can","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.409639127Z","response":" also","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.417480073Z","response":" be","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.425250071Z","response":" seen","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.434030379Z","response":" on","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.441586322Z","response":" the","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.44953472Z","response":" left","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.457934826Z","response":" side","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.466621776Z","response":" of","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.474522367Z","response":" the","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.482164977Z","response":" image","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.489806331Z","response":",","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.497422616Z","response":" adding","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.505029007Z","response":" some","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.512655886Z","response":" gre","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.520270742Z","response":"enery","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.527950115Z","response":" to","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.535610963Z","response":" the","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.543517032Z","response":" snowy","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.551320555Z","response":" landscape","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.559147856Z","response":".","done":false}
{"model":"moondream:1.8b","created_at":"2025-03-07T12:21:02.566976927Z","response":"","done":true,"done_reason":"stop","context":[18233,25,220,58,9600,12,15,60,198,198,24564,4892,628,23998,25,220,198,464,2939,2523,257,24296,3715,351,6729,9505,262,2323,13,1318,389,734,5621,286,18791,290,43183,287,262,12699,11,530,900,5140,1474,262,3641,12,9464,1735,286,262,5739,290,1194,900,22765,3371,262,826,1735,13,383,18791,1656,284,307,925,286,4898,393,6147,11,981,262,43183,423,257,2092,1486,13,317,279,8426,4618,460,635,307,1775,319,262,1364,1735,286,262,2939,11,4375,617,10536,24156,284,262,46742,10747,13],"total_duration":1117786111,"load_duration":20986309,"prompt_eval_count":740,"prompt_eval_duration":369000000,"eval_count":91,"eval_duration":717000000}