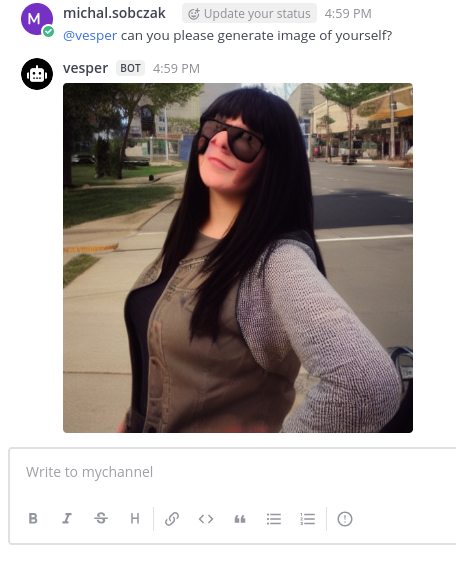
Upload image, enter text prompt and press Start Generation. It is as easy as it looks like.
So we take some pre-trained models, feed it with some text prompt and starting image and things happen on GPU side to generate frame by frame and merge it into motion picture. It is sometimes funny, creepy but every time it is interesting to see live coming into still pictures and making video out of them.
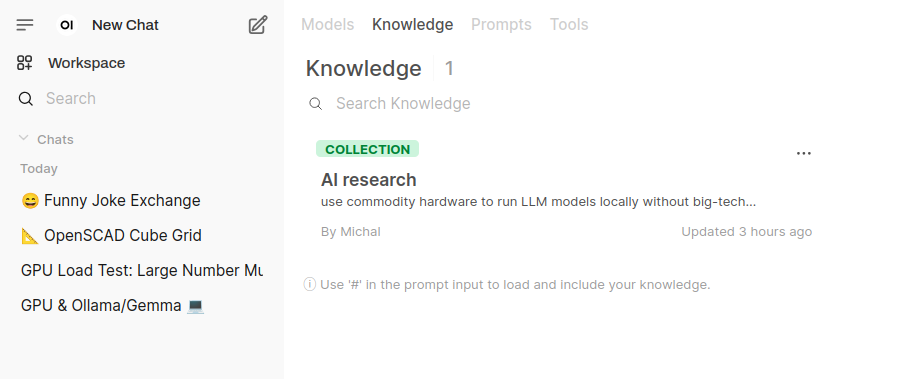
User Interface
On the left you upload starting image and write prompt below it describing what it should look like in video output.
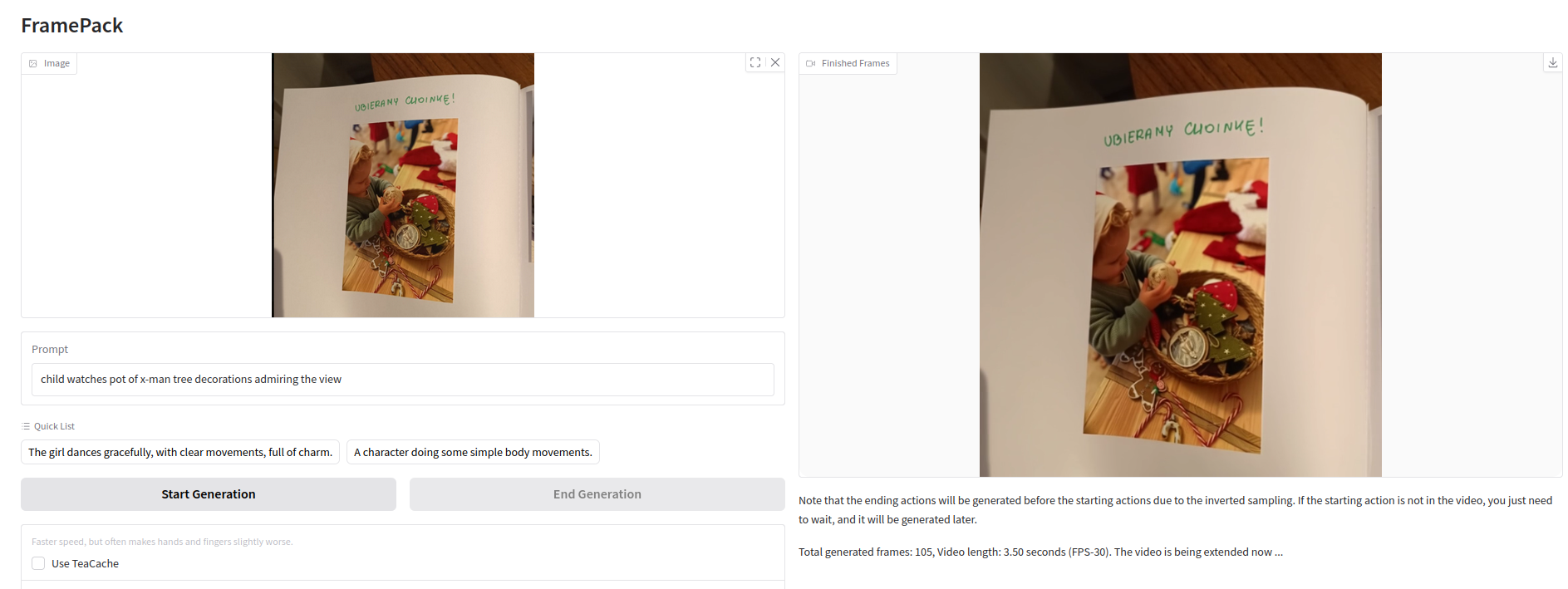
Once started, do to leave application page as the generation process will disappear. I cannot see any option to bring back what it is running in the background. Maybe there is option I am not aware of.
Video generation process
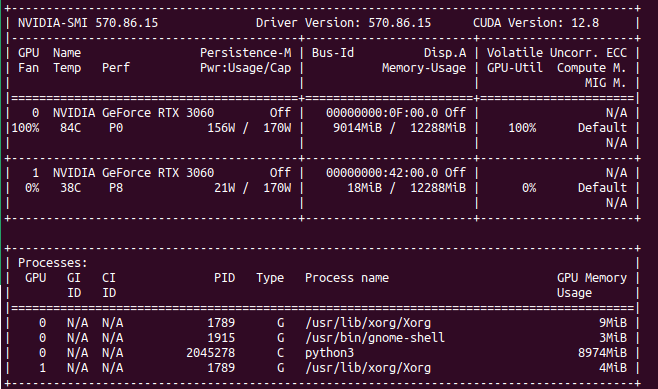
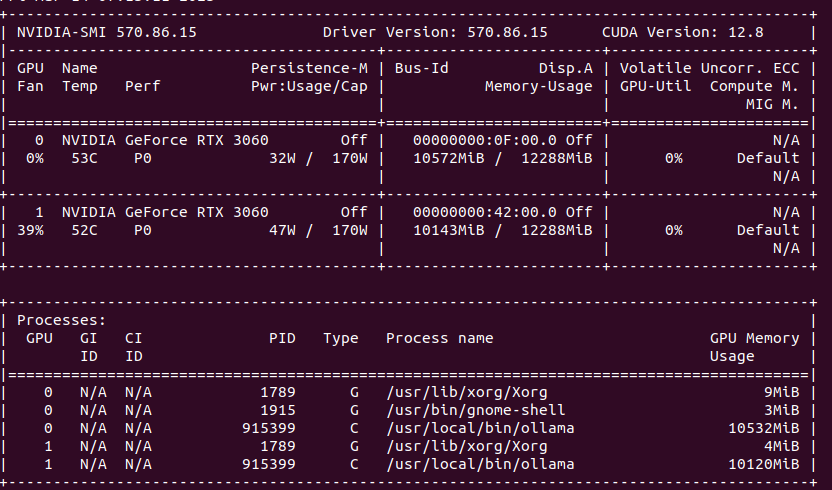
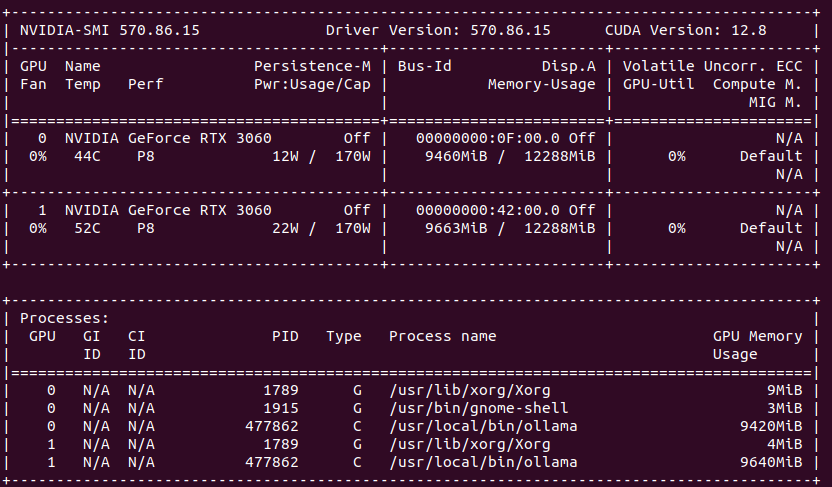
Processing takes place on GPU. Need to have at least RTX 30xx and above on Linux/Windows platform. The more powerful your GPU is the fastest you will get frames generated. Single frame takes from few seconds up to one minute. To speed up (with a cost of lower details and more mistakes) you can use TeaCache.
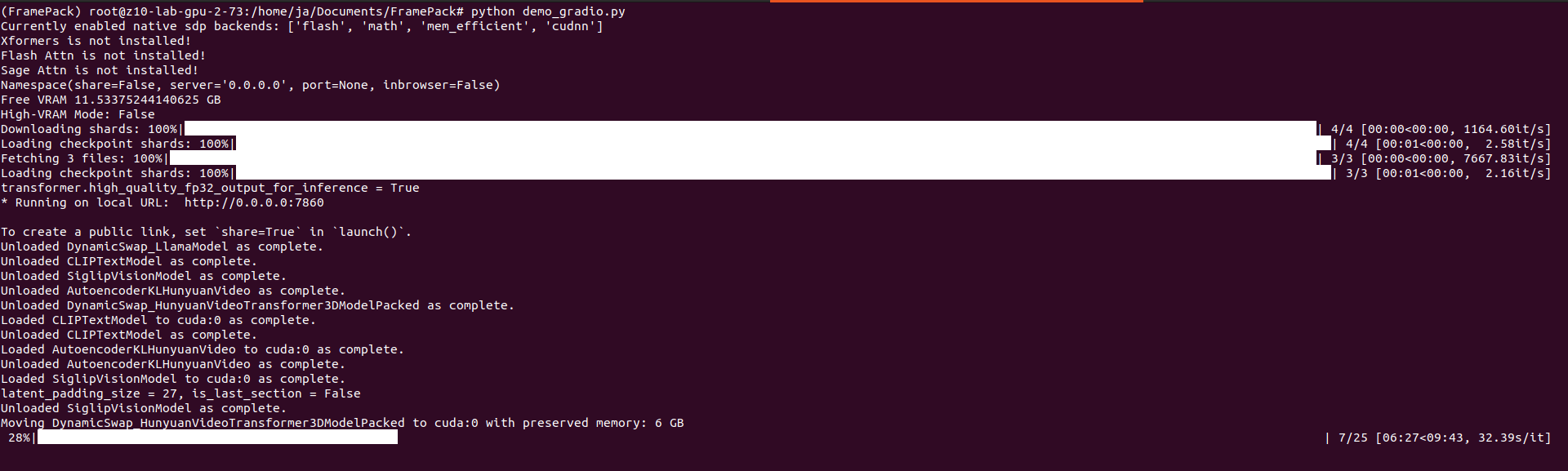
You can provide seed and change total video length, steps, CFG scale, GPU preserved memory amount and MP4 compression. From the system point of view, I assiged 64 GB of RAM to VM and FramePack ate over 40 GB, but proceeds only on 1 vCPU. Not entirely sure how it would positively impact performance, but I support it would if supporting proper multiprocessing/multithreading.

On my RTX 3060 12GB single 1 second generates around 10 – 15 minutes as each second is made of 30 frames which is not exactly configurable. It seems (although not confirmed) that model has been pre-trained to generate 30 FPS (that info can be found in their issue tracker).
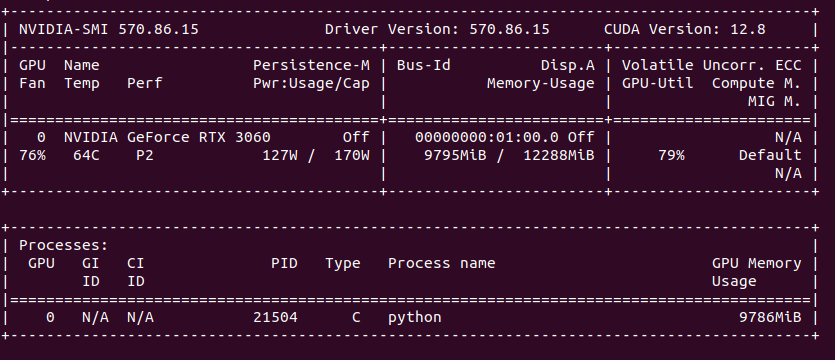
My VM setup suffers from memory latency, which is noticeable comparing to bare metal Ubuntu installation. Still I prefer to do this VM-way, because I have much more elasticity in terms of changing environments, systems and drivers which then would be quite difficult, cumbersome to archieve with bare metal system. So any performance penalty coming from virtualization is fine for me.
Installation
Be boring part. First start with installing Python 3.10:
sudo apt update
sudo apt install software-properties-common -y
sudo add-apt-repository ppa:deadsnakes/ppa
sudo apt update
Then clone repository and install dependencies:
https://github.com/lllyasviel/FramePack.git
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
pip install -r requirements.txt
Prepare FramePack repository in virtual environment:
python3.10 -m venv FramePack
source FramePack/bin/activate
I got one error during torchvision installation:
torch 2.7.0+cu126 depends on typing-extensions...
This problem can be mitigated by:
pip install --upgrade typing-extensions
And then you are good to go:
python demo_gradio.py
UI will start on http://127.0.0.1:7860/