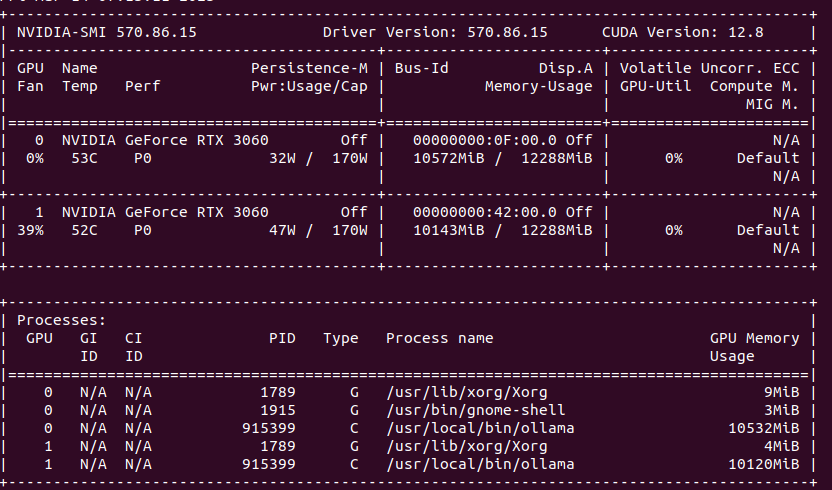
Utilize both CPU, RAM and GPU computational resources
With Ollama you can use not only GPU but also CPU with regular RAM go run LLM models, like DeepSeek-R1:70b. Of course you need to have fast both CPU and RAM and have plenty of it. My Lab setup contains 24 vCPU (2 x 6 cores * 2 threads) and from 128 to 384 GB of RAM. Once started, Ollama allocates 22.4GB in RAM (RES) and 119GB of vritual memory. It occupies 1200% CPU utilization causing system load to go up to 12. However, CPU utilization is only 50% in total.
It loads over 20GB in RAM, puts system on load

On GPU side it allocates 2 x 10GB of VRAM, but stays silient in terms of actual cores usage.
Thinking…
DeepSeek-R1 stars with “Thinking” part, where it makes conversation with itself about its knowledge and tries to better understand questions aloud. It could ask me those questions, but chooses not to and tries to pick whatever it thinks its best at the moment. Fully on CPU at the moment, no extensive GPU usages.
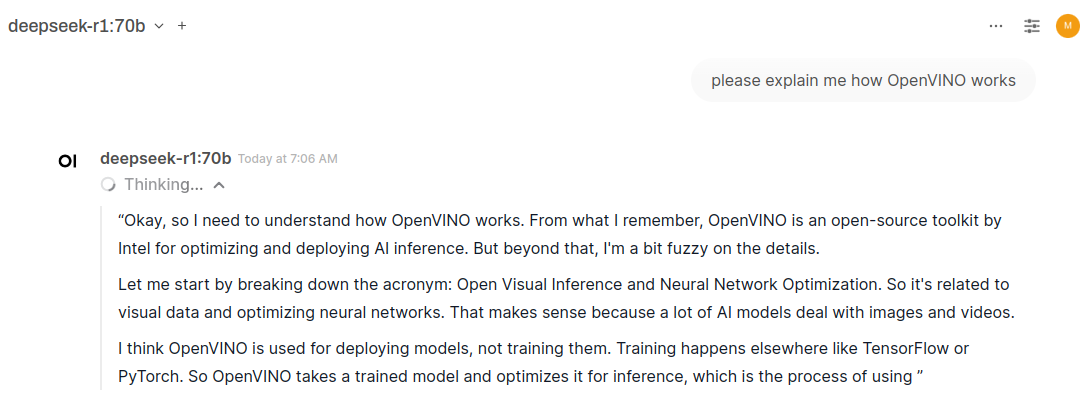
It generates this “Thinking” stage for minutes… and after an hour or so it gave full answer:
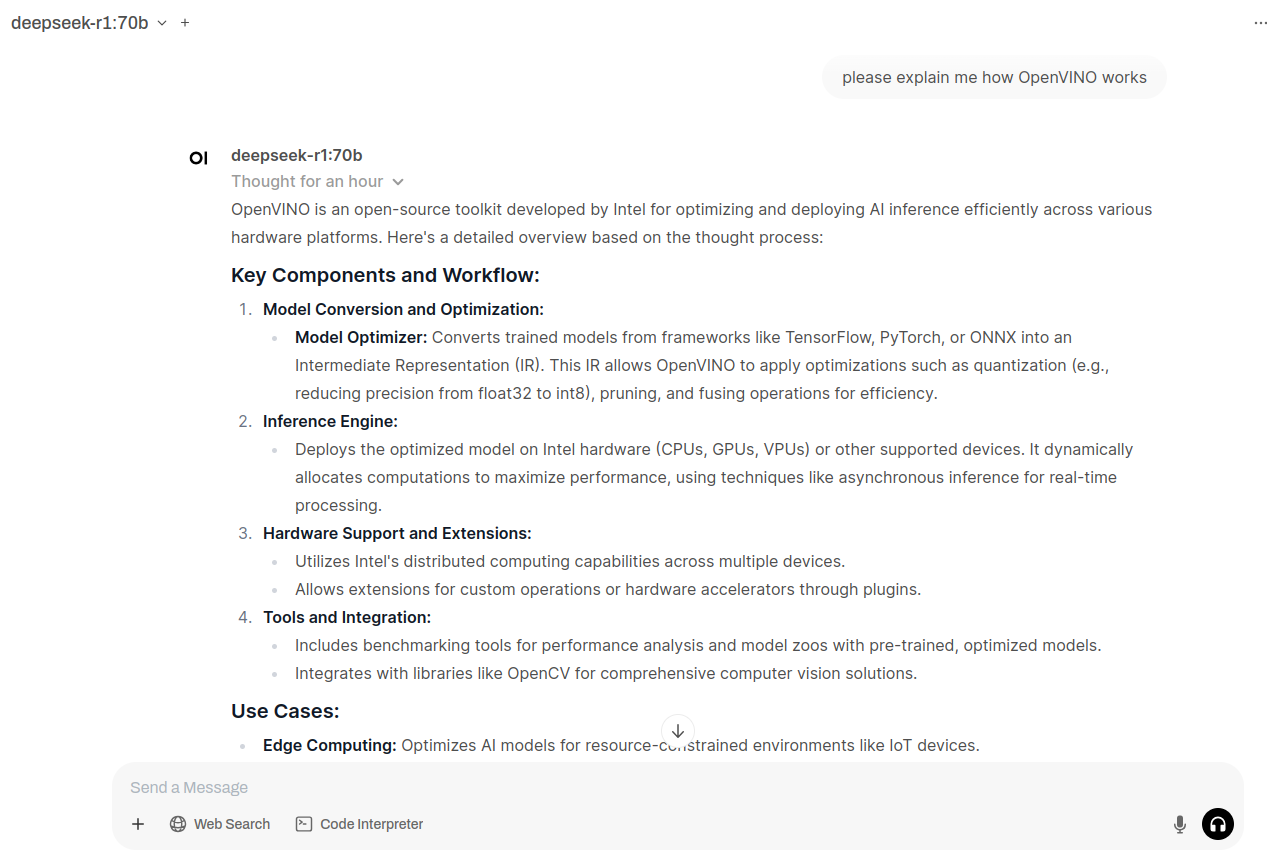
So, it works. Just very very slow.