With Ollama paired with Gemma3 model, Open WebUI with RAG and search capabilities and finally Automatic1111 running Stable Diffusion you can have quite complete set of AI features at home in a price of 2 consumer grade GPUs and some home electricity.
With 500 iterations and image size of 512×256 it took around a minute to generate response.

I find it funny to be able to generate images with AI techniques. Tried Stable Diffusion in the past, but now with help of Gemma and integratino with Automatic1111 on WebUI, it’s damn easy.
Step by step
- Install Ollama (Docker), pull some models
- Run Open WebUI (Docker)
- Install Automatic1111 with stable diffusion
Prerequisites
You can find information how to install and run Ollama and OpenWebUI in my previous
Automatic1111 with stable diffusion
Stable Diffusion is latent diffusion model originally created in German universities and later developed by Runway, CompVis, and Stability AI in 2022. Automatic1111 also created in 2022 is a hat put atop of stable diffusion allowing it be consumed in more user-friendly manner. Open WebUI can integrate Automatic1111, by sending text requests to automatic’s API . To install it in Ubuntu 24 you will be to install Python 3.10 (preffered) instead of shipped with OS Python 3.12:
sudo apt install git software-properties-common -y
sudo add-apt-repository ppa:deadsnakes/ppa -y
sudo apt install python3.10-venv -y
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui && cd stable-diffusion-webui
python3.10 -m venv venv
./webui.sh
As you can see one uses venv. If your Ubuntu got only Python 3.11 then you are good to go with it. I start Automatic1111 with some additional parameters to help me with debugging things:
./webui.sh --api --api-log --loglevel DEBUG
Open WebUI integration
Go to Admin setting and look for “Images”:
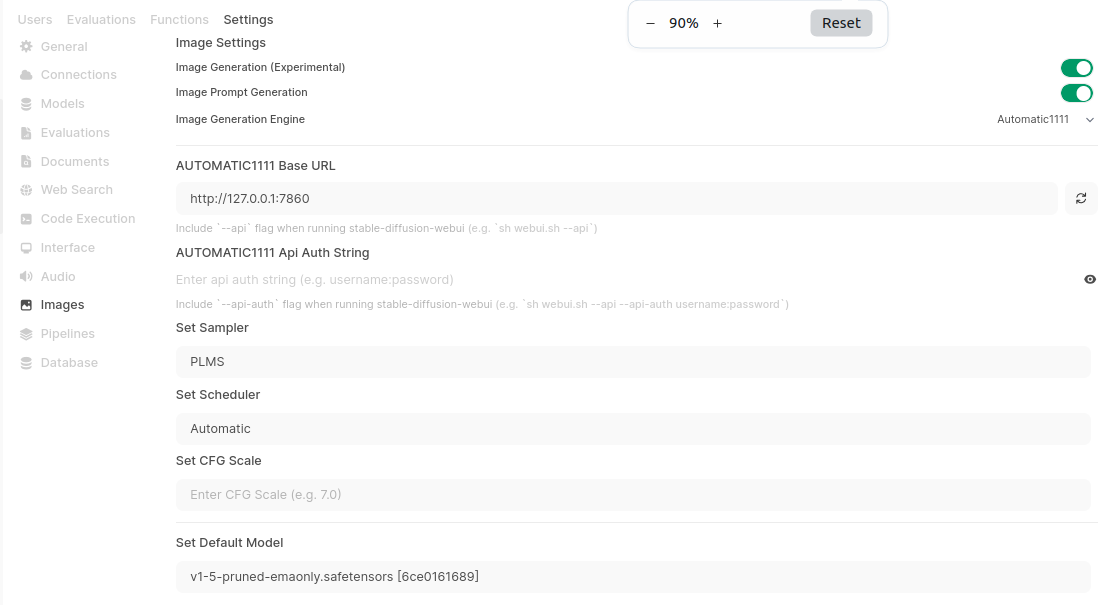
Enable image generation, prompt generation and select Automatic1111 as engine. Enter Base URL with should be http://127.0.0.1:7860 by default, in case you run WebUI and Automatic1111 on the same machine. Next are sample, scheduler, CFG scale and model.
I find last two parameters, the most important from user-perspective. Those are image size and number of steps. The last one sets iterations number for diffusion, noise processing. The more you set, the longer it takes to accomplish. Image size also seems to be correlated with final product as it implies how big the output should be.

1000 iterations
Set number of iterations to 1000 and asked to generate visualization. It took around 30 minutes and grew up to 9GB of VRAM.

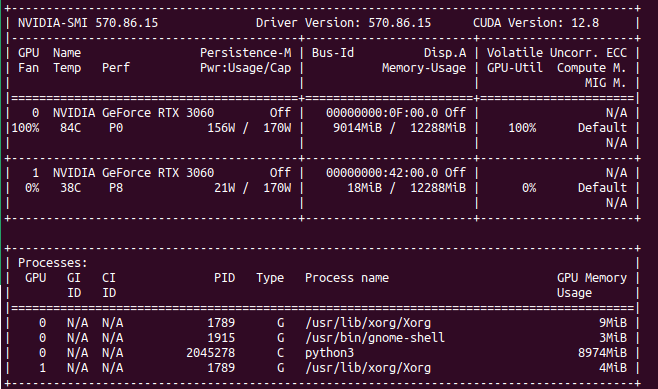
Result is quite intesting. But I’m not exactly sure what I am looking at. Is it one image or are these two images combined? Frankly speaking, I can wait even and hour to get something useful. Back in 2023 and 2024 I tried commercial services to generate designs and they failed to accomplish even simple tasks. So instead of paying 20 USD or so, I prefer to buy GPU and use some home electricity to generate very similar images. This is just my preference.

Conclusion
I am not going to pay OpenAI. These tools provide much fun and productivity.