Full fine-tuning of mlx-community/Qwen2.5-3B-Instruct-bf16
Recently I posted article on how to train LORA MLX LLM here. Then I asked myself how can I export or convert such MLX model into HF or GGUF format. Even that MLX has such option to export MLX into GGUF most of the time it is not supported by models I have been using. From what I recall even if it does support Qwen it is not version 3 but version 2 and quality suffers by such conversion. Do not know why exactly it works like that.
So I decided to give a try with full fine-tuning using transformers, torch and accelerate.
Input data
In terms of input data we can use the same format as with LORA MLX LLM training. So there are two kind of files which is train.jsonl and valid.jsonl with the following format:
{"prompt":"This is the question", "completion":"This is the answer"}
Remember that this is full training, not only low rank adapters. So it is a little bit harder to get proper results. It is crucial to get as much good quality data as possible. I take source documents and run augumentation process using Langflow.
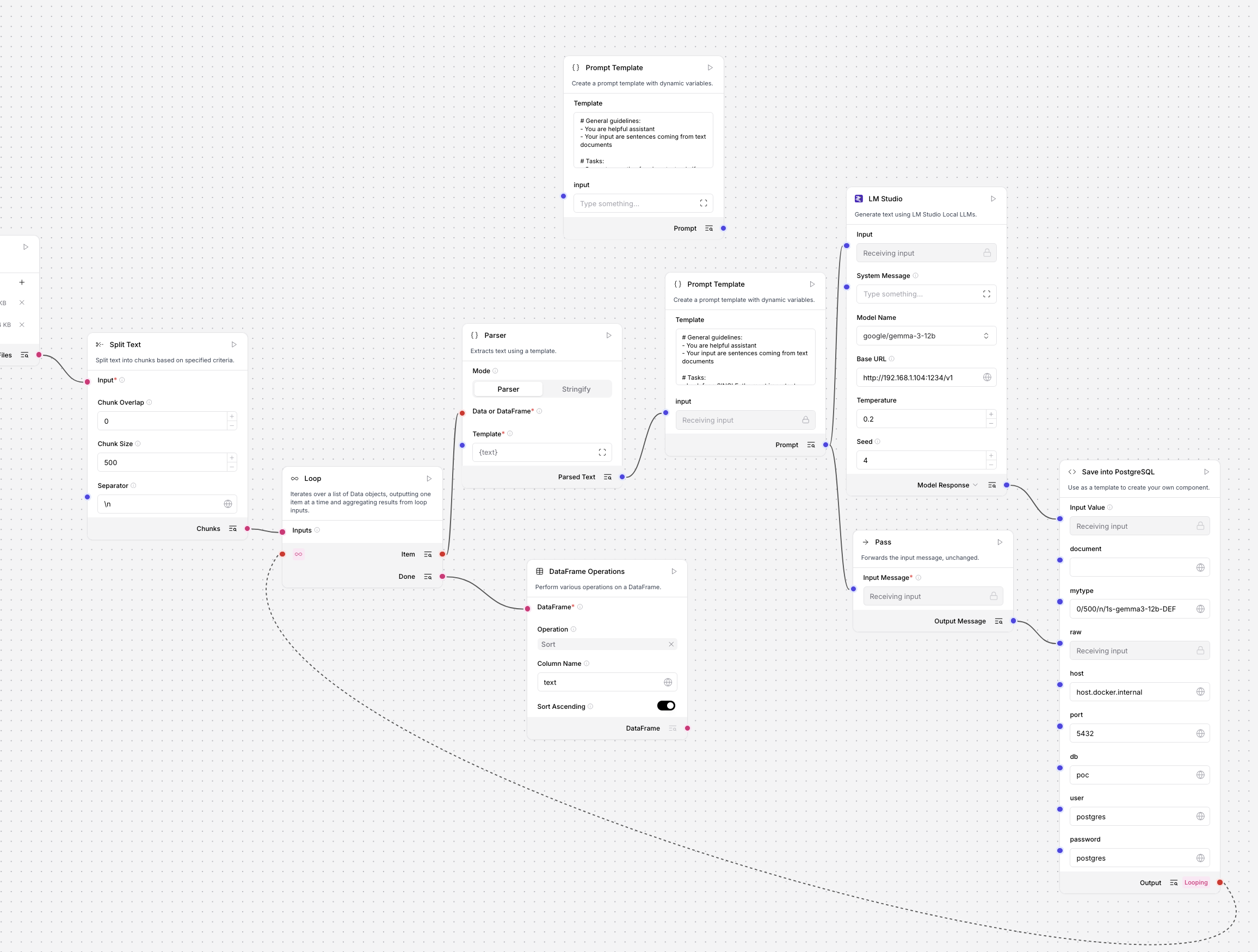
Full fine-tuning program
Next there is source code for training program code. You can see that you need transformers, accelerate, PyTorch and Datasets. The first and the only parameter is output folder for weights. After the training is done there are some test questions to be asked in order to verify quality of trained model.
import os
from typing import List, Dict, Tuple
from datasets import Dataset
from transformers import (
AutoTokenizer,
AutoModelForCausalLM,
TrainingArguments,
Trainer,
DataCollatorForLanguageModeling
)
import torch
import json
from typing import List, Dict
folder = os.sys.argv[1]
def prepare_dataset() -> Dataset:
records: List[Dict[str, str]] = []
with open("./data-folder/train.jsonl", "r", encoding="utf-8") as f:
for line_no, line in enumerate(f, start=1):
line = line.strip()
if not line:
continue
try:
obj = json.loads(line)
if isinstance(obj, dict):
records.append(obj)
print(obj)
else:
print(f"Linia {line_no}: nie jest słownikiem, pomijam.")
except json.JSONDecodeError as e:
print(f"Linia {line_no}: błąd JSON ({e}) — pomijam.")
return Dataset.from_list(records)
def format_instruction(example: Dict[str, str]) -> str:
return f"<|user|>{example['prompt']}\n <|assistant> {example['completion']}"
def tokenize_data(example: Dict[str, str], tokenizer: AutoTokenizer) -> Dict[str, torch.Tensor]:
formatted_text = format_instruction(example)
return tokenizer(formatted_text, truncation=True, padding="max_length", max_length=128)
def fine_tune_model(base_model: str = "mlx-community/Qwen2.5-3B-Instruct-bf16") -> Tuple[AutoModelForCausalLM, AutoTokenizer]:
tokenizer = AutoTokenizer.from_pretrained(base_model)
tokenizer.save_pretrained(folder)
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained(
base_model,
torch_dtype=torch.float32
)
model.to("mps")
dataset = prepare_dataset()
tokenized_dataset = dataset.map(
lambda x: tokenize_data(x, tokenizer),
remove_columns=dataset.column_names
)
split = tokenized_dataset.train_test_split(test_size=0.1)
train_dataset = split["train"]
eval_dataset = split["test"]
training_args = TrainingArguments(
output_dir=folder,
num_train_epochs=4,
per_device_train_batch_size=2,
gradient_accumulation_steps=12,
learning_rate=5e-5,
weight_decay=0.001,
max_grad_norm = 1.0,
warmup_ratio=0.10,
lr_scheduler_type="cosine",
bf16=True,
fp16=False,
logging_steps=10,
save_total_limit=2,
evaluation_strategy="steps",
eval_steps=50,
save_strategy="steps",
save_steps=100,
load_best_model_at_end=True,
metric_for_best_model="loss",
greater_is_better=False,
gradient_checkpointing=True,
group_by_length=True
)
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
data_collator=data_collator,
)
trainer.train()
return model, tokenizer
def generate_response(prompt: str, model: AutoModelForCausalLM, tokenizer: AutoTokenizer, max_length: int = 512) -> str:
formatted_prompt = f"<|user|>{prompt} <|assistant|>"
inputs = tokenizer(formatted_prompt, return_tensors="pt").to(model.device)
outputs = model.generate(
**inputs,
max_length=max_length,
temperature=0.7,
num_return_sequences=1,
)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
if __name__ == "__main__":
model, tokenizer = fine_tune_model()
test_prompts: List[str] = [
"Question 1",
"Question 2",
"Question 3",
"Question 4",
"Question 5",
"Question 6"
]
for prompt in test_prompts:
response = generate_response(prompt, model, tokenizer)
print(f"\nPrompt: {prompt}")
print(f"Response: {response}")
Parametrization
Lets take a look at the configuration parameters:
num_train_epochs=4,
per_device_train_batch_size=2,
gradient_accumulation_steps=12,
learning_rate=5e-5,
weight_decay=0.001,
max_grad_norm = 1.0,
warmup_ratio=0.10,
lr_scheduler_type="cosine",
bf16=True,
fp16=False,
logging_steps=10,
save_total_limit=2,
evaluation_strategy="steps",
eval_steps=50,
save_strategy="steps",
save_steps=100,
load_best_model_at_end=True,
metric_for_best_model="loss",
greater_is_better=False,
gradient_checkpointing
The story is as follows:
Within 4 epochs and size of 2 batches at a time but accumulated with 12x factor we have been learning at the speed of 5e-5. Our warmup takes 10% of runtime. We run cosine decay with certain weight_decay and gradients normalization. We try to use BF16, do not use FP16 but your milage may vary. Logging take place at every 10 steps (for training loss). We eval every 50 steps (for validation loss). However we save every 100 steps. We save best checkpoint in the end and 2 checkpoints at maximum.
HF to GGUF conversion
After training finished we convert this HF format into GGUF in order to run it using LMStudio.
# get github.com/ggml-org/llama.cpp.git
# initialize venv and install libraries
python convert_hf_to_gguf.py ../rt/model/checkpoint-x/ --outfile ../rt/model/checkpoint-x-gguf
However it is recommended only do this after test questions gives any good results. Otherwise it will be pointless.
Running a training session
During the training session we may observe:
{'loss': 26.942, 'grad_norm': 204.8477783203125, 'learning_rate': 1.923076923076923e-05, 'epoch': 0.16}
{'loss': 17.2971, 'grad_norm': 62.03092956542969, 'learning_rate': 3.846153846153846e-05, 'epoch': 0.31}
{'loss': 16.1831, 'grad_norm': 55.732086181640625, 'learning_rate': 4.99613632163459e-05, 'epoch': 0.47}
{'loss': 15.3985, 'grad_norm': 52.239620208740234, 'learning_rate': 4.952806974561518e-05, 'epoch': 0.63}
{'loss': 14.6101, 'grad_norm': 47.203189849853516, 'learning_rate': 4.862157403595598e-05, 'epoch': 0.79}
20% | 50/252 [10:00<28:39, 8.51s/it]
{'eval_loss': 1.1458975076675415, 'eval_runtime': 10.0881, 'eval_samples_per_second': 16.852, 'eval_steps_per_second': 2.181, 'epoch': 0.79}
{'loss': 13.5673, 'grad_norm': 40.04380416870117, 'learning_rate': 4.7259364450857096e-05, 'epoch': 0.94}
{'loss': 10.3291, 'grad_norm': 40.06776428222656, 'learning_rate': 4.5467721110696685e-05, 'epoch': 1.11}
{'loss': 8.4045, 'grad_norm': 33.435096740722656, 'learning_rate': 4.3281208889462715e-05, 'epoch': 1.27}
{'loss': 8.2388, 'grad_norm': 40.08720779418945, 'learning_rate': 4.0742010579737855e-05, 'epoch': 1.42}
{'loss': 8.0016, 'grad_norm': 34.05099105834961, 'learning_rate': 3.7899113090712526e-05, 'epoch': 1.58}
40% | 100/252 [18:07<21:10, 8.36s/it]
{'eval_loss': 1.0009825229644775, 'eval_runtime': 27.7629, 'eval_samples_per_second': 6.123, 'eval_steps_per_second': 0.792, 'epoch': 1.58}
{'loss': 7.9294, 'grad_norm': 36.029380798339844, 'learning_rate': 3.4807362379317025e-05, 'epoch': 1.74}
{'loss': 7.7119, 'grad_norm': 33.554954528808594, 'learning_rate': 3.1526405346999946e-05, 'epoch': 1.9}
50% | 126/252 [24:58<19:44, 9.40s/it]
{'loss': 6.2079, 'grad_norm': 26.597759246826172, 'learning_rate': 2.8119539115370218e-05, 'epoch': 2.06}
{'loss': 3.6895, 'grad_norm': 36.123207092285156, 'learning_rate': 2.4652489880792128e-05, 'epoch': 2.22}
{'loss': 3.7563, 'grad_norm': 24.915979385375977, 'learning_rate': 2.1192144906604876e-05, 'epoch': 2.38}
60% | 150/252 [31:57<24:00, 14.12s/it]
...
On my Mac Studio M2 Ultra with 64GB of RAM it takes from 55 up to 60GB or memory to run a training session:

Not sure if it just fit or shinks down a little bit just to fit exactly within mu memory limits.
Finally:
{'eval_loss': 1.0670475959777832, 'eval_runtime': 31.049, 'eval_samples_per_second': 5.475, 'eval_steps_per_second': 0.709, 'epoch': 3.96}
{'train_runtime': 4371.782, 'train_samples_per_second': 1.398, 'train_steps_per_second': 0.058, 'train_loss': 7.671164320574866, 'epoch': 3.99}
Conversion
If after test questions we would decide that current weights are capable then we can conver HF format into GGUF two checkpoints, checkpoint-200 and checkpoint-252 as well as some other files like vocab and tokenizer:
added_tokens.json
checkpoint-200
checkpoint-252
merges.txt
runs
special_tokens_map.json
tokenizer.json
tokenizer_config.json
vocab.json
Single checkpoint:
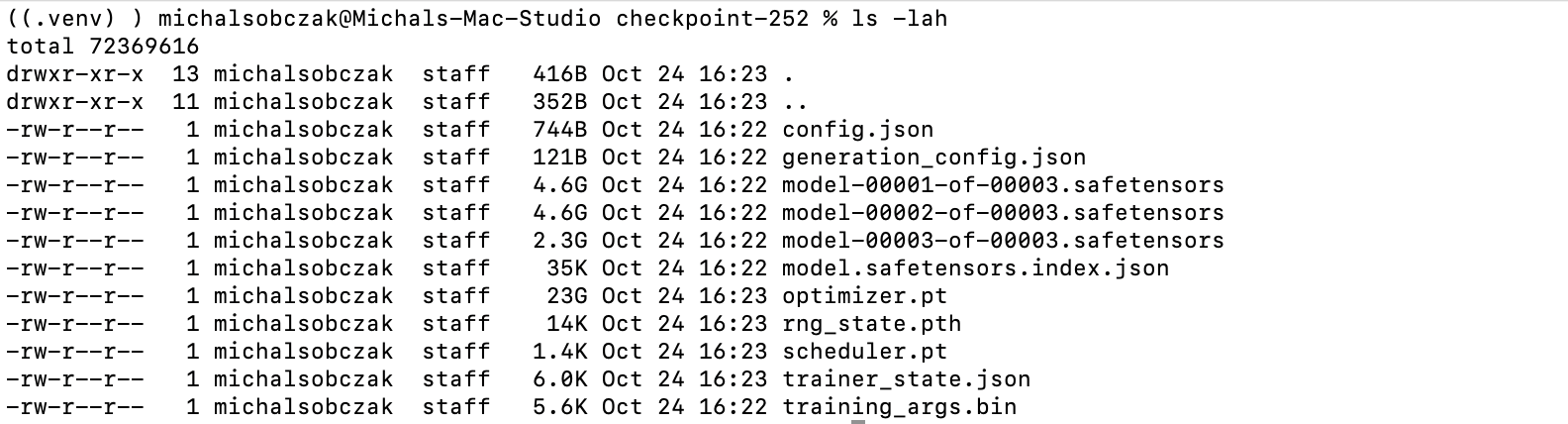
We need to copy tokenizer from base model path into checkpoint path:
cp tokenizer.json checkpoint-252
and then run conversion:
python convert_hf_to_gguf.py ../rt/model/checkpoint-252 --outfile ../rt/model/checkpoint-252-gguf
Judge the quality yourself, especially comparing to LORA trainings. In my personal opinion full fine-tuning requires much higher level of expertise than just training a subset of full model.