
Asking BLOOM-560M “what is love?” it replies with “The woman who had my first kiss in my life had no idea that I was a man”. wtf?!
Intro
I’ve been into parallel computing since 2021, playing with OpenCL (you can read about it here), looking for maximizing devices capabilities. I’ve got pretty decent in-depth knowledge about how computational process works on GPUs and I’m curious how the most recent AI/ML/LLM technology works. And here you have my little introduction to LLM topic from practical point-of-view.
Course of Action
- BLOOM overview
- vLLM
- Transformers
- Microsoft Azure NV VM
- What’s next?
What is BLOOM?
It is a BigScience Large Open-science Open-access Multilingual language model. It based on transformer deep-learning concept, where text is coverted into tokens and then vectors for lookup tables. Deep learning itself is a machine learning method based on neural networks where you train artificial neurons. BLOOM is free and it was created by over 1000 researches. It has been trained on about 1.6 TB of pre-processed multilingual text.
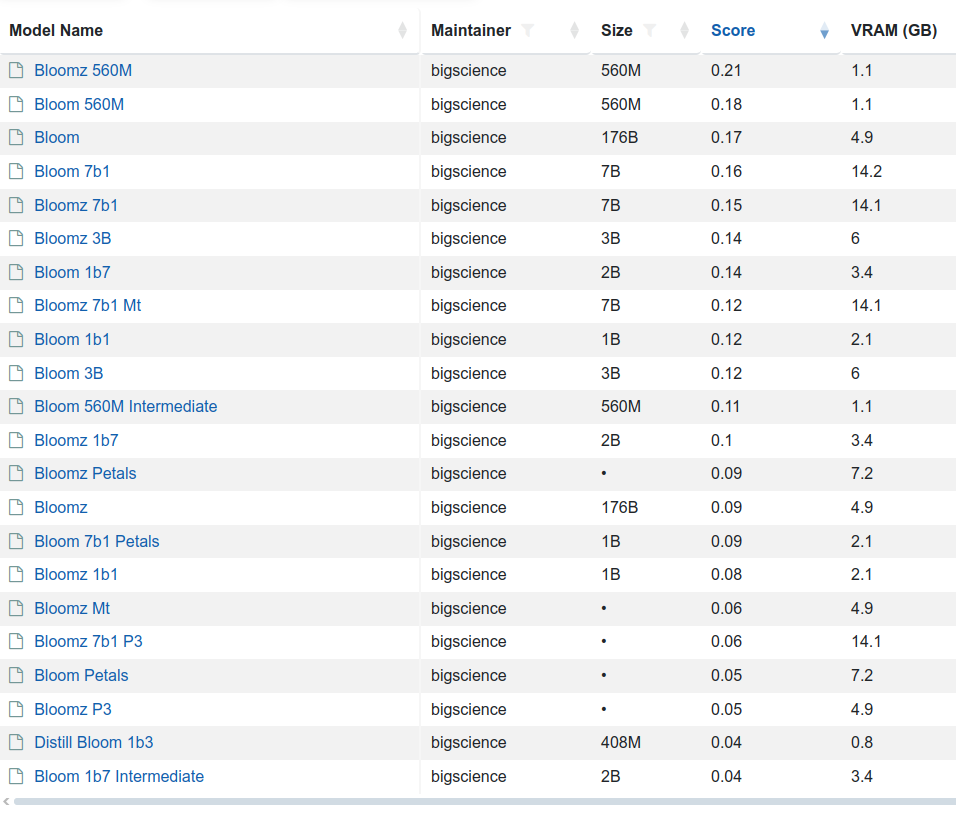
There are few variants of this model 176 billion elements (called just BLOOM) but also BLOOM 1b7 with 1.7 billion elements. There is even BLOOM 560M:
- to load and run 176B you need to have 350 GB VRAM with FP32 and half with FP16
- to load and run 1B7 you need somewhere between 10 and 12 GB VRAD and half with FP16
So in order to use my NVIDIA GeForce RTX 3050 Ti with 4GB RAM I would either need to run with BLOOM 560M which requires 2 to 3 GB VRAM and even below 2 GB VRAD in case of using FP16 mixed precision or… use CPU. So 176B requires 700 GB RAM, 1B7 requires 12 – 16 GB RAM and 560M requires 8 – 10 GB RAM.
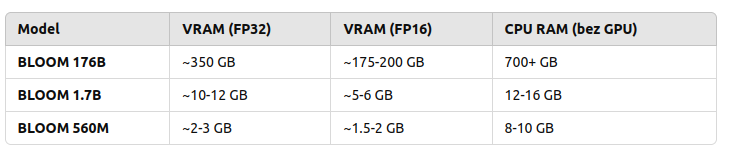
Are those solid numbers? Lets find out!
vLLM
“vLLM is a Python library that also contains pre-compiled C++ and CUDA (12.1) binaries.”
“A high-throughput and memory-efficient inference and serving engine for LLMs”
You can download (from Hugging Face, company created in 2016 in USA) and serve language models with these few steps:
pip install vllm
vllm serve "bigscience/bloom"
And then once it’s started (and to be honest it won’t start just like that…):
curl -X POST "http://localhost:8000/v1/chat/completions" \
-H "Content-Type: application/json" \
--data '{
"model": "bigscience/bloom"
"messages": [
{"role": "user", "content": "Hello!"}
]
}'
You can back up your vLLM runtime using GPU or CPU but also ROCm, OpenVINO, Neuron, TPU and XPU. It requires GPU compute capability 7.0 or higher. I’ve got my RTX 3050 Ti which has 8.6, but my Tesla K20Xm with 6GB VRAD has only 3.5 so it will not be able to use it.
Here is the Python program:
from vllm import LLM, SamplingParams
model_name = "bigscience/bloom-560M"
llm = LLM(model=model_name, gpu_memory_utilization=0.6, cpu_offload_gb=4, swap_space=2)
question = "What is love?"
sampling_params = SamplingParams(
temperature=0.5,
max_tokens=10,
)
output = llm.generate([question], sampling_params)
print(output[0].outputs[0].text)
In return, there is either:
[rank0]: torch.OutOfMemoryError: CUDA out of memory. Tried to allocate 736.00 MiB. GPU 0 has a total capacity of 3.81 GiB of which 73.00 MiB is free. Including non-PyTorch memory, this process has 3.73 GiB memory in use. Of the allocated memory 3.56 GiB is allocated by PyTorch, and 69.88 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management (https://pytorch.org/docs/stable/notes/cuda.html#environment-variables)
or the following:
No available memory for the cache blocks. Try increasing `gpu_memory_utilization` when initializing the engine.
I may try later to check it out on bigger GPU but as for now, I will try to run it using transformers library which is the next topic.
Transformers
So I picked the same BLOOM 560M model. First, you need to install the following main packages and plenty of dependencies:
pip install transformers
pip install torch
pip install accelerate
Source code of Python program using those libraries is as follows:
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("bigscience/bloom-560m")
model = AutoModelForCausalLM.from_pretrained(
"bigscience/bloom-560m",
device_map="auto",
torch_dtype="auto"
)
def ask_bloom(question, max_length=100, temperature=0.7):
inputs = tokenizer(question, return_tensors="pt").to(model.device)
output = model.generate(
inputs['input_ids'],
max_length=max_length,
temperature=temperature,
pad_token_id=tokenizer.eos_token_id,
do_sample=True
)
answer = tokenizer.decode(output[0], skip_special_tokens=True)
return answer
question = "What is love?"
answer = ask_bloom(question)
print(f"Q: {question}\nAnwser: {answer}")
To run:
python3 transformers-torch.py

It will download the model and execute in Python program.
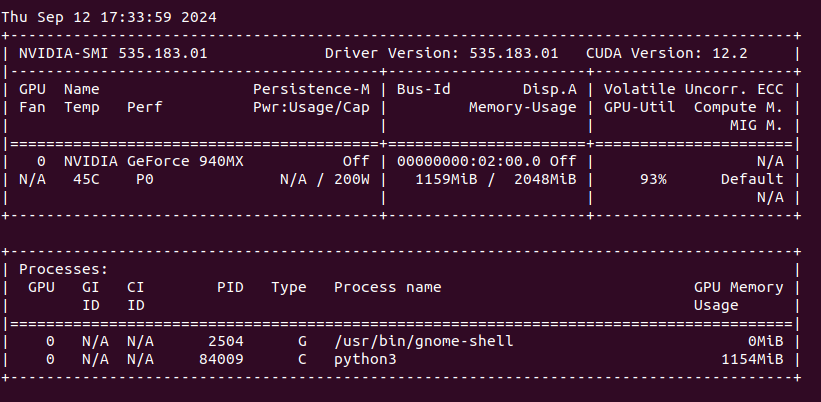
We can see that my NVIDIA GeForce 940MX with 2 GB VRAM is loaded around 60% with over 90% utilization (results from nvidia-smi).
“What is love?”. Anwser is as follows:
What is love? She never asked me the question but I am the one who has to give my answer. She is a beautiful, beautiful, very beautiful woman. The first thing you know about love is that it is the most complicated thing in the world. I was so shocked when I saw the man I thought I was marrying. My life was over. The woman who had my first kiss in my life had no idea that I was a man. She was so shocked. She said something
Next I asked for “The sun is shining and?”
I love this scene and I like when it comes to it. The sun, the sky and all the other stars are bright and I love that! I really enjoy this scene and it sets the scene for the rest of the story. It seems like the characters are just going about their day and the sun is shining. The world seems to be in its perfect place and everything is beautiful. I love the lighting in this scene and the warmth of the sunlight that
Does it make any sense? What is a concept of “sense” at all? Anyway it works, somehow. Lets find out the other possibilities.
Microsoft Azure N-series virtual machines
Instead of buying MSI Vector, ASUS ROG, Lenovo Legion Pro, MSI Raider or any kind of ultimate gaming laptops you go to Azure and pick on their NV virtual machines. Especially that they have 14 and 28 GB of VRAM onboard. It costs around 400 Euro per month, but you will not be using it all the time (I suppose).
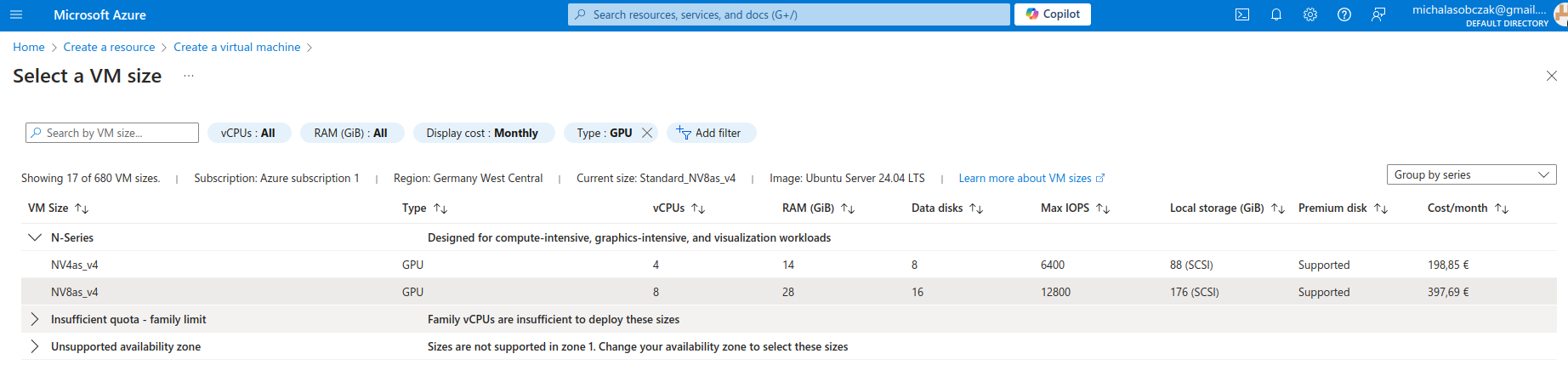
We have:
root@z92-az-bloom:/home/adminadmin# lspci
0002:00:00.0 VGA compatible controller: Advanced Micro Devices, Inc. [AMD/ATI] Vega 10 [Instinct MI25 MxGPU/MI25x2 MxGPU/V340 MxGPU/V340L MxGPU]
And I was not so sure how to use AMD GPU, so instead I decided to requests for a quote increase:
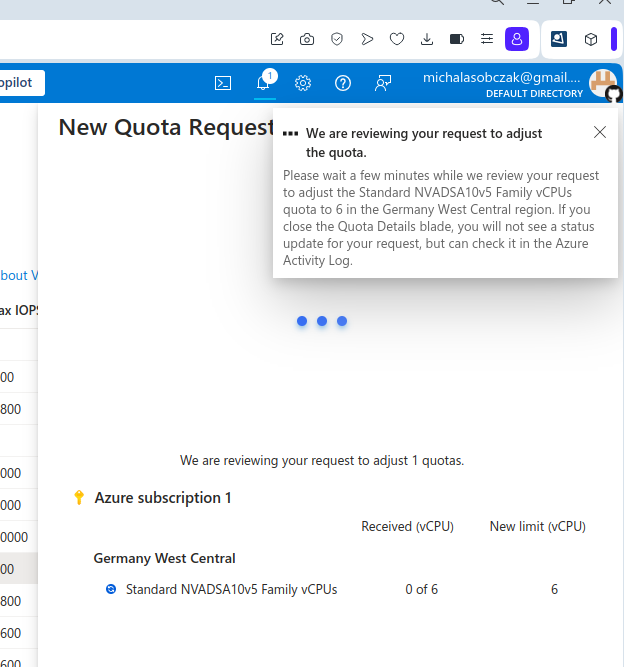
However I got rejected on my account with that request:
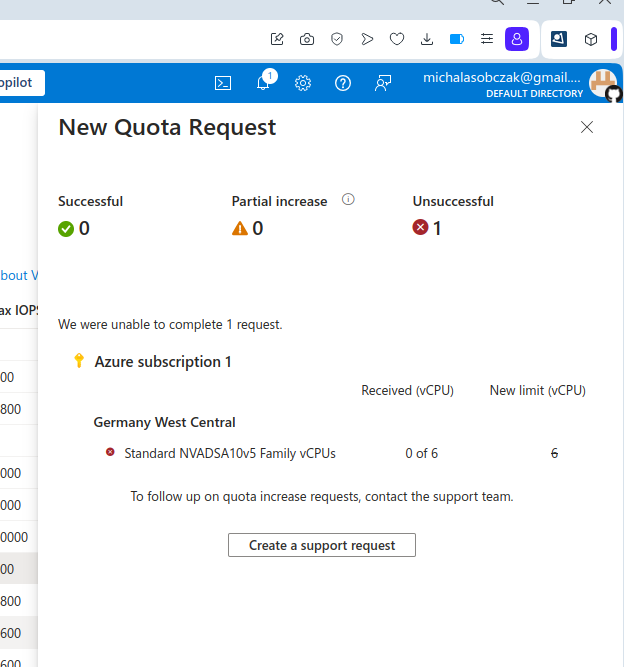
Unfortantely changing parameters and virtual machine types did not change the situation, I got still rejected and neeeded to submit support ticket to Microsoft in order to manually process it. So until next time!
What’s next to check?
AWS g6 and Hetzner GEX44. Keep reading!
Further reading
- Bloom 1b7 by bigscience, https://huggingface.co/bigscience/bloom-1b7
- List of Bloom models, https://llm.extractum.io/list/?mtr=bigscience
- Transformers library, https://huggingface.co/docs/hub/transformers
- vLLM:
- Other models, https://www.forbes.com/sites/bernardmarr/2024/05/07/the-best-open-source-generative-ai-models-available-today/