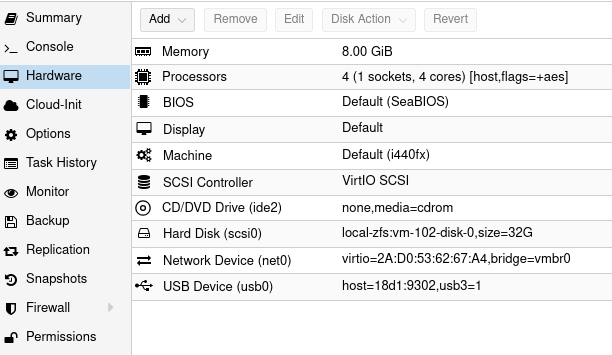
No, cant use Tesla K20xm with 6GB VRAM for modern computation as it has Compute Capability parameter lower than required 7.0. Here you have table of my findings about libraries/frameworks, required hardware and its purpose.

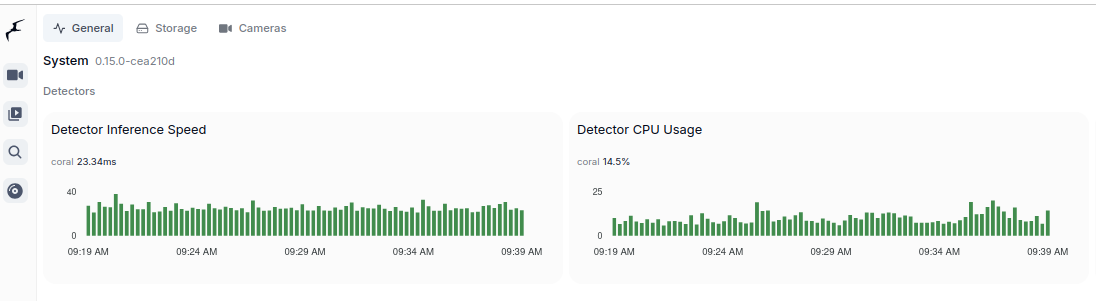
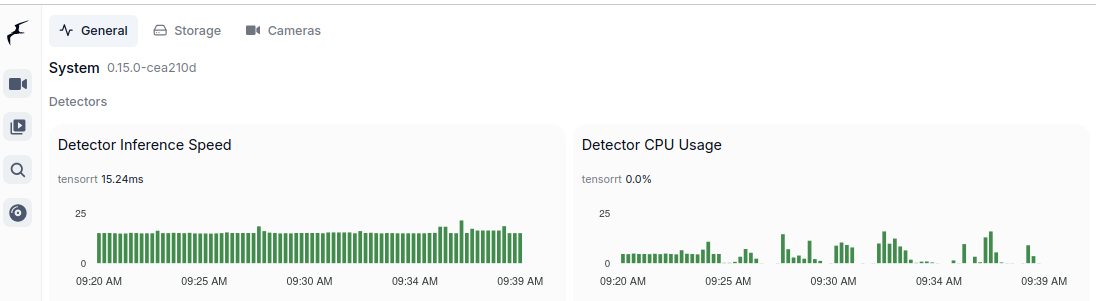
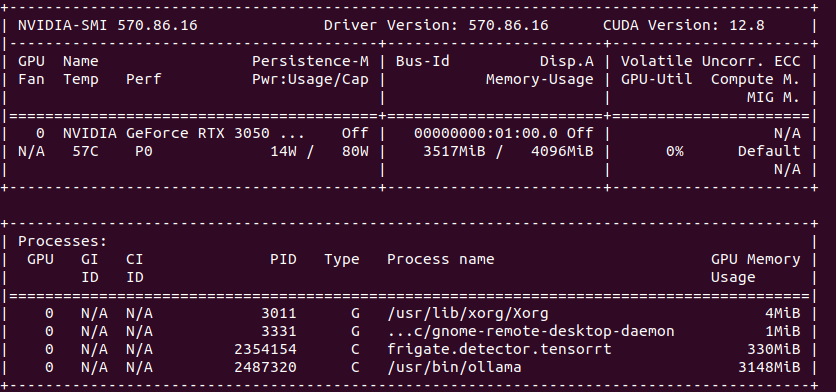
I started with DeepStack, where I was able to run API server for object detection, Frigate has support for it. Later on, with TensorRT on NVIDIA GPU I can run Yolov7x-640 model also for object detection, Frigate works well with it. With Google Coral TPU USB module we can run SSD MobileNet or EfficientDet models with great power efficency for good price. Ollama with moondream is both general purpose and computer vision description if run with moondream model, works great with Frigate for scene outlook. Last thing I tried is OpenVINO which enables Intel devices for object detection, works great with ssdlite_mobilenet_v2 model.
| Library/Framework | Type | Requirement | Purpose |
| DeepStack | AI API server | NVIDIA CC 5.0 (3.5/3.7?) | Object detection |
| TensorRT | deep learning inference SDK | NVIDIA CC 5.0 (3.0/3.5?) | Object detection |
| Google Coral TPU | neural networks accelerator | n/a | Object detection |
| Ollama/moondream:1.8b | vision language model | NVIDIA CC 7.0 (5.0?) | Computer vision |
| Exo/Llama | pipeline parallel inference | NVIDIA CC 7.0 (5.0?) | General purpose |
| OpenVINO Intel iGPU + CPU | deep learning toolkit | Intel iGPU, CPU 6th gen | General purpose |
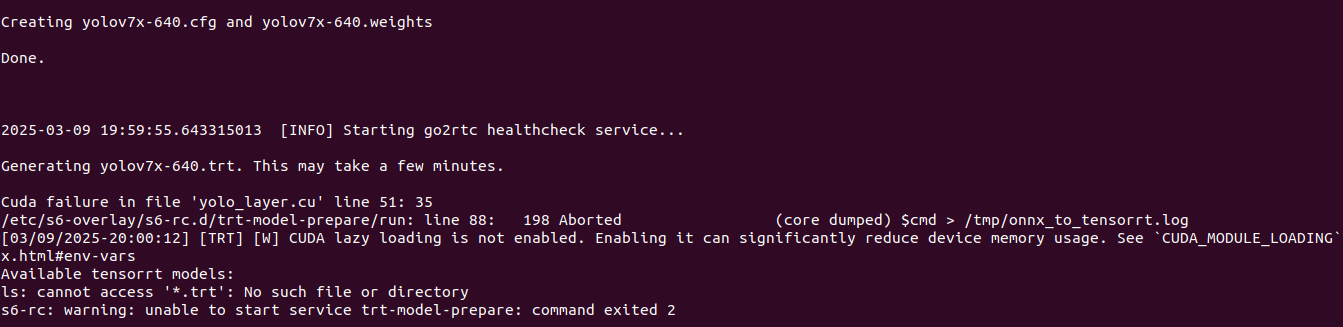
ResortRT: requirements validation
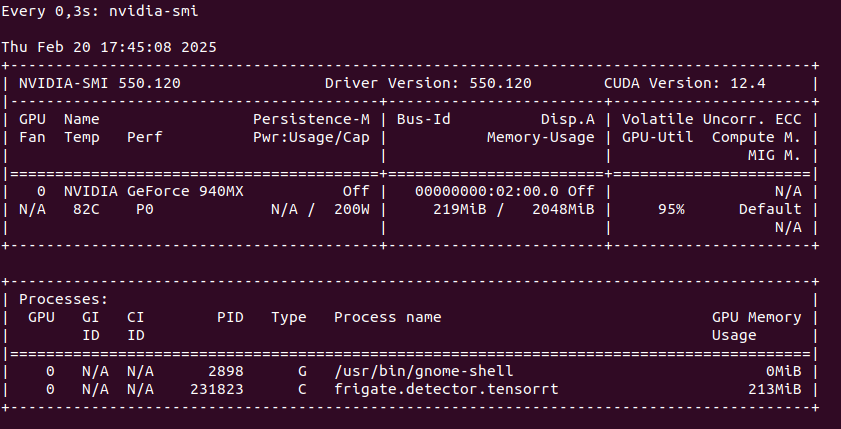
It is not entirely true that TensorRT is supported by CC 3.5 as I have tested on Tesla K20xm and it gives me error. So I would rather say, that is may be supported given some special constraints and not exactly with Yolov7x-640 model generated on Frigate startup.
Exo: Linux/NVIDIA does not work at all
With Exo I have issues, no idea why it does not work on Linux/NVIDIA and gives gibberish results and being totally unstable with loads of smaller/bigger bugs. Llama running on the same OS and hardware on Ollama server works just fine. I will give it a try later, maybe on different release, hardware and some tips from Exo Labs, of how to actually run it.
My recommendation
For commodity, consumer hardware usage I recommend using OpenVINO, TensorRT which enables already present hardware. Buy Coral TPU if you lack of computational power. I do not see reason to run DeepStack as previously mentioned are available out-of-the-box.