Use Microsoft Azure AI Services to analyze images, voice, documents. No AI/ML or coding skills required. Responsible AI applies by EU AI act. Formerly Cognitive Services.
Course of Action
- Create AI Services multi-account in Azure
- Run computer vision OCR on image
What is Microsoft Azure?
It is Microsoft’s public cloud platform offering broad range of products and services, including virtual machines, managed containers, databases, analytics platforms as well as AI Services. Major competitors of Azure are Amazon AWS and Google’s GCP.
What are AI Services (formerly Cognitive Services)?
It is a set of various services concerning recognition and analysis procedures based on already trained ML models (or even traditional programming techniques). You can use it to describe documents, run OCR tasks, face recognition etc. Actually, those services tend to be categorized under Cognitive Services section, which concerns recognition which is a synonym of cognitive. Name change process which happend in July 2023 was more-or-less rebranding and provided non breaking changes only as a part of marketing. It is obvious that AI services would sell better than Cognitive Services.
Create AI multi-service account in Azure portal
In order to create Microsoft Azure AI Services multi-service account you need to have valid Azure subscription, either Free Trial or regular account. Type “AI” in search field in portal.azure.com and you will find this service thru service catalog.
It is worth menitioning that you get “Responsible AI Notice” which relates to AI Act which includes European Union, USA and UK. It defines what AI/ML models can do and what should not allow. Accoring to KPMG source it covers among others: social scoring, recruitment and deep-fake disclosure as the most crucial areas which require regulations. What about the rest of the world? Well, it might be same as with CO2 emissions or plastic garbage recycling. situation.
Deployment process in Azure is especially meaningful when speaking about configurable assets with data. However in terms of deploying services it is a matter of linking them to our account, so the deployment process of AI Services finishes within seconds.
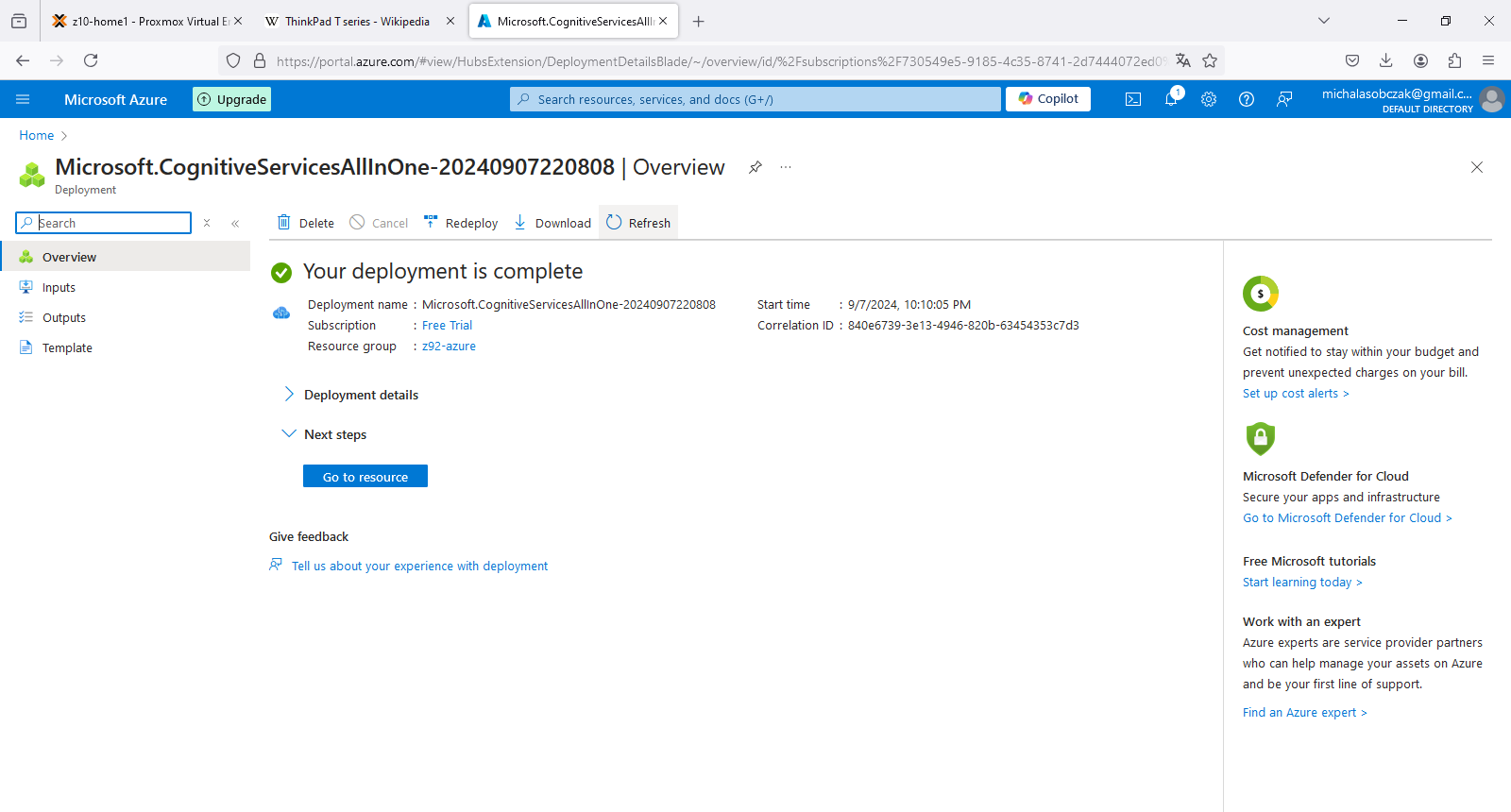
AI Services account overview
To use Azure AI services you need to go to Resource Management, Keys and Endpoint. You will know to which Endpoint you should send your API calls/requests and what is the access key. This key is then mapped to “Ocp-Apim-Subscription-Key” header which should be passed during HTTP call.

As for S0 standad pricing tier on Free Tier subscription, estimate 1 000 calls to API (requests made) would cost less than 1 Euro. It might be “cheap” however it is starting point of pricing and I suspect that it might be actually a different value in real production use case scenario especially when speaking about decision making (still could be ML based only) services and not only those services which could be replaced by traditional programming techniques, which is notabene OCR processes which are present on the market for few decades already.
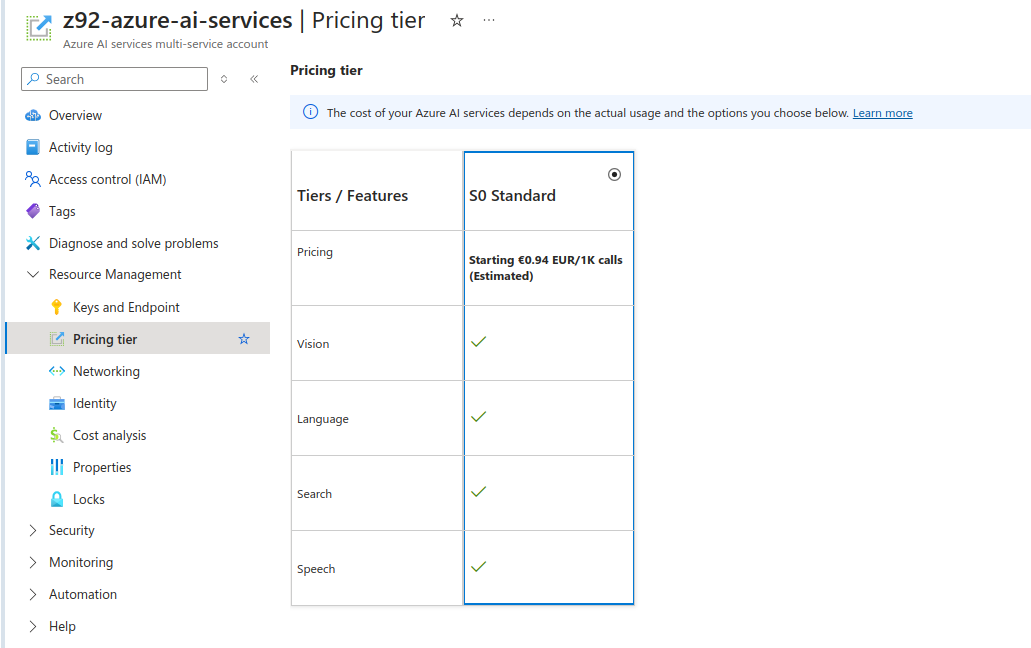
Run example recognition task
Instead of programming (aka coding) in various SDKs for AI Services (Python, JavaScript etc) you can also invoke such services within HTTP request using curl utility. As far as I know every Windows 10 and 11 should have curl present. As for Linux distributions you most probably have curl already installed.
So, in order to invoke recognition task, pass subscription key (here replaced by xxx), point at specific Endpoint URL and pass url parameter which should be some publicly available image on which recognition service will run over. I found out that not every feature is available in every Endpoint. In that case, you would need to modify “features” parameter:
curl -H "Ocp-Apim-Subscription-Key: xxx" -H "Content-Type: application/json" "https://z92-azure-ai-services.cognitiveservices.azure.com//computervision/imageanalysis:analyze?features=read&model-version=latest&language=en&api-version=2024-02-01" -d "{'url':'https://michalasobczak.pl/wp-content/uploads/2024/08/image-6.png'}"I passed this image for analysis, which contains dozen of rectangular boxes with text inside. It should should be straighforward to get proper results as text is not rotated, it is written in machine font and color contrast at proper value.
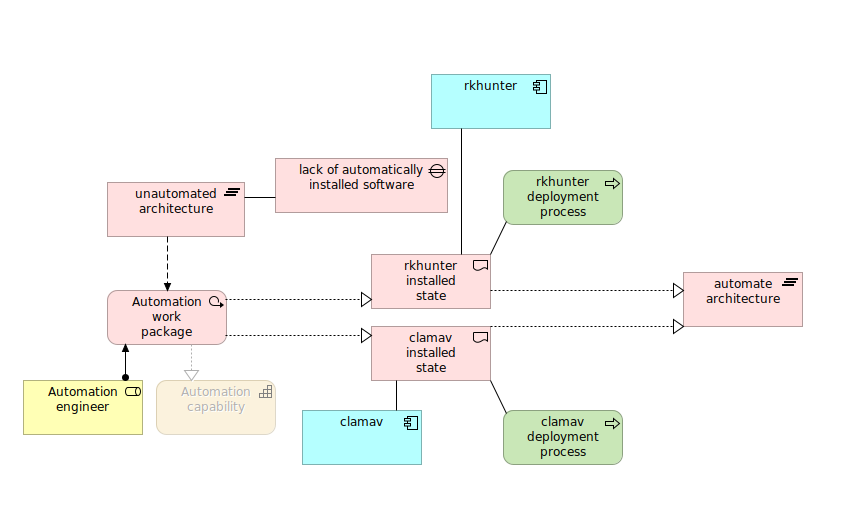
In return we receive the following JSON formatted output. We can see that it properly detected word “rkhunter” as well as “process”. However we need to provide additional layer of processing in order to merge those adjacent words in separate lines to make them phrases instead of just separate words.
{
"modelVersion":"2023-10-01",
"metadata":{
"width":860,
"height":532
},
"readResult":{
"blocks":[
{
"lines":[
{
"text":"rkhunter",
"boundingPolygon":[
{
"x":462,
"y":78
},
{
"x":519,
"y":79
},
{
"x":519,
"y":92
},
{
"x":462,
"y":91
}
],
...
"words":[
{
"text":"process",
"boundingPolygon":[
{
"x":539,
"y":447
},
{
"x":586,
"y":447
},
{
"x":586,
"y":459
},
{
"x":539,
"y":459
}
],
"confidence":0.993
}
]
}
]
}
]
}
}
Conclusion
I think that price-wise this AI Service, formerly known as Cognitive Services, it is reasonable way of running recognition tasks in online environment. We could include such recognition into our applications for further automation, in, for instance ERP FI invoice processing.