Ollama with WebUI on 2 “powerful” GPUs feels like commercial GPTs online
I thought that Exo would do the job and utilize both of my Lab servers. Unfortunately, it does not work on Linux/NVIDIA with my setup and following official documentation. So I went back to Ollama and I found it great. I have 2 x NVIDIA RTX 3060 with 12GB VRAM each giving me in total 24GB which can run Gemma3:27b or DeepSeek-r1:32b.
- Gemma3:27b takes in total around 16 – 18GB of GPU VRAM
- DeepSeek-r1:32b takes in total around 19GB of GPU VRAM
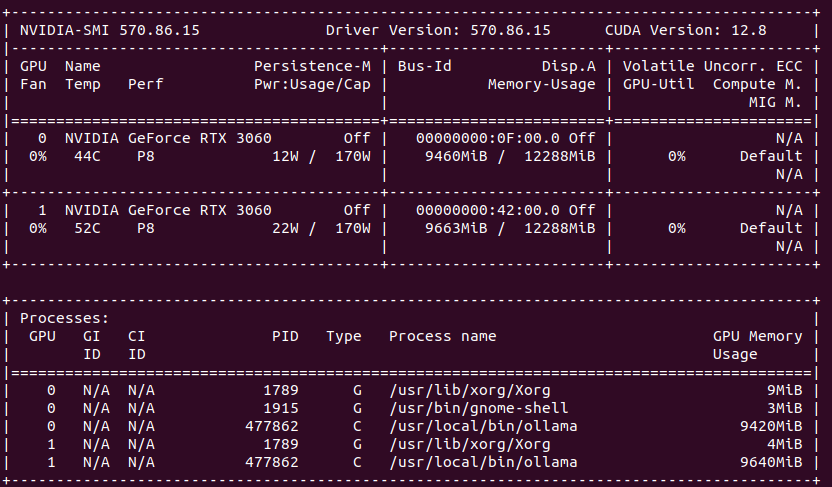
Ollama can utilize both GPUs in my system which can be seen in nvidia-smi. How to run Ollama in Docker with GPU acceleration you can read in my previous article.
So why running on multiple GPUs is important?
With more VRAM available in the system you can run bigger models as they require to load data into video card memory for processing. As mentioned earlier, I tried with Exo as well as vLLM, but only Ollama supports it seamlessly without any hassle at all. Unfortunately Ollama, as far as I know, does not support distrubuted inference. There has been work under construction way back in Nov 2024, however it is not clear if it is going to be in main distribution.
https://github.com/ollama/ollama/issues/7648

Running more than one CPU and GPU also requires powerful PSU. Mine got 1100W and can handle 2 x Xeon processors, up to 384 GB of RAM and at least 2 full sized full powered GPUs. Idling it takes around 250 – 300 W. At full GPU power it draws 560 – 600W.
Can I install more than two GPUs?
Yes, we can. However in my Lab computer I do not have more than 2 high power PCI-E slots so further card may be underpowed. Still it is quite interesting thing to check out in the near future.
How about Open WebUI?
Instead of using command line prompt with Ollama, it is better in terms of productivity to use web user interface called Open WebUI. It can be run from Docker container as follows:
sudo docker run -d --network=host -v open-webui:/app/backend/data -e OLLAMA_BASE_URL=http://127.0.0.1:11434 --name open-webui --restart always ghcr.io/open-webui/open-webui:main
Then, WebUI is available on 127.0.0.1:8080.
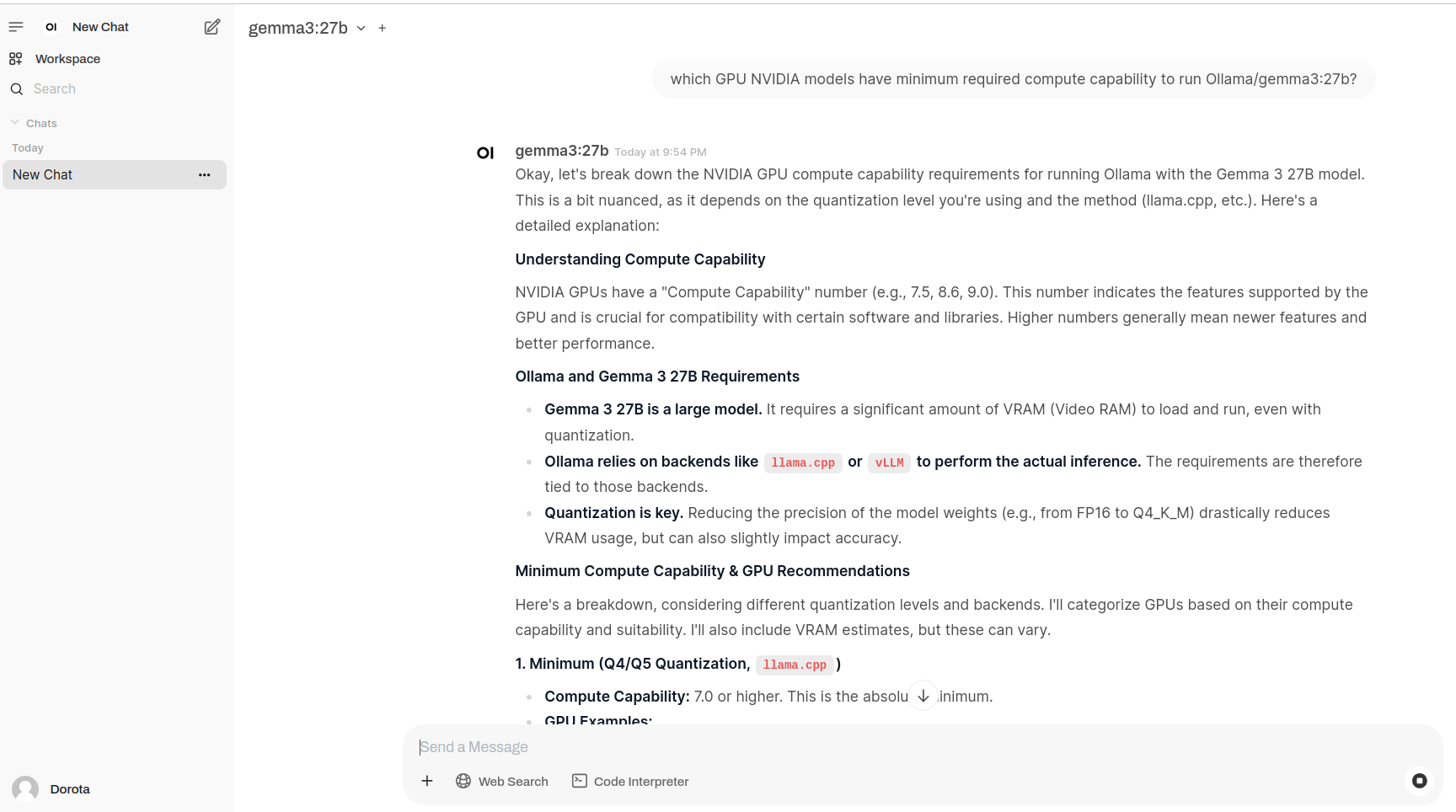
Side-by-side execution
It allows to run side-by-side models questioning.
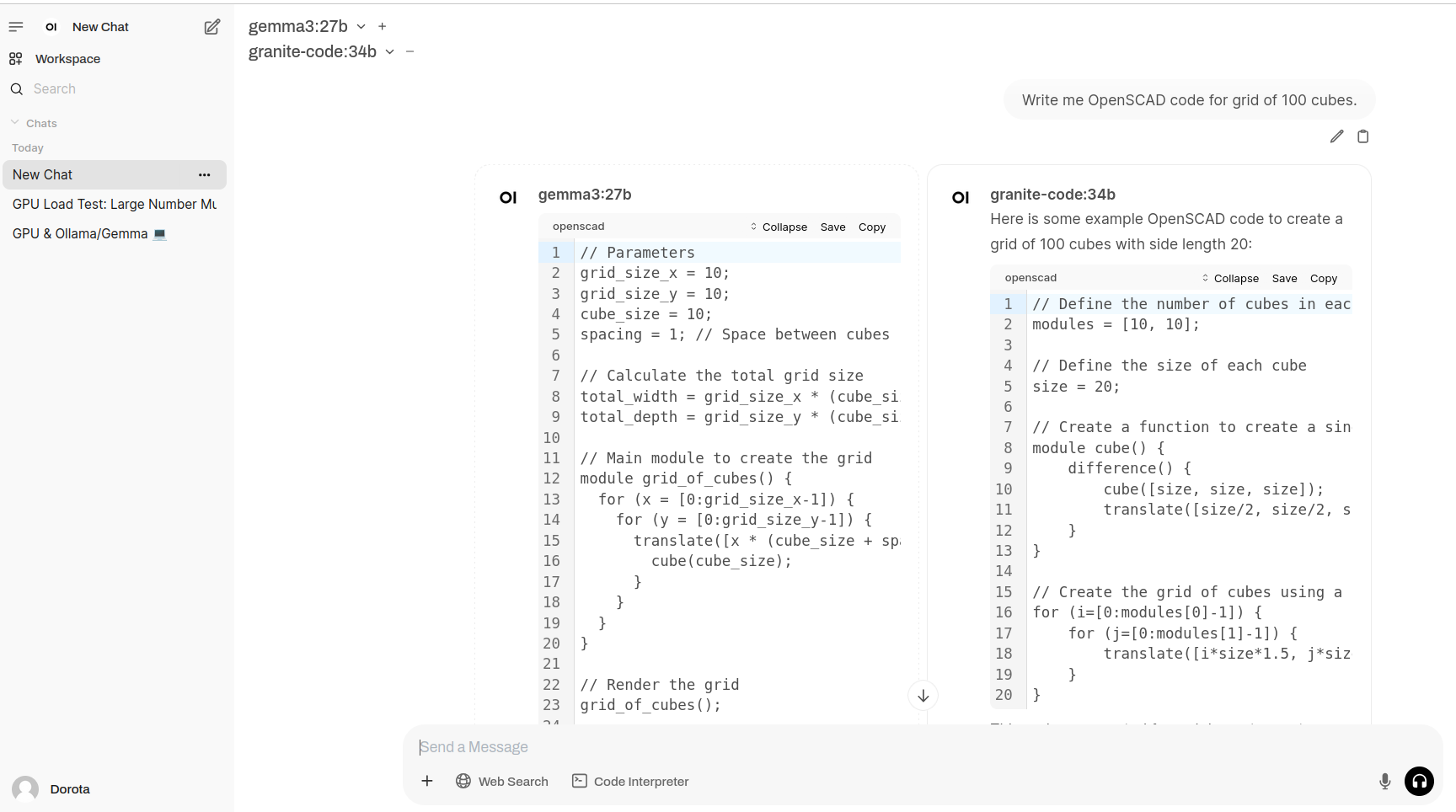
Parametrization
With WebUI you can modify inference parameters (advanced params).
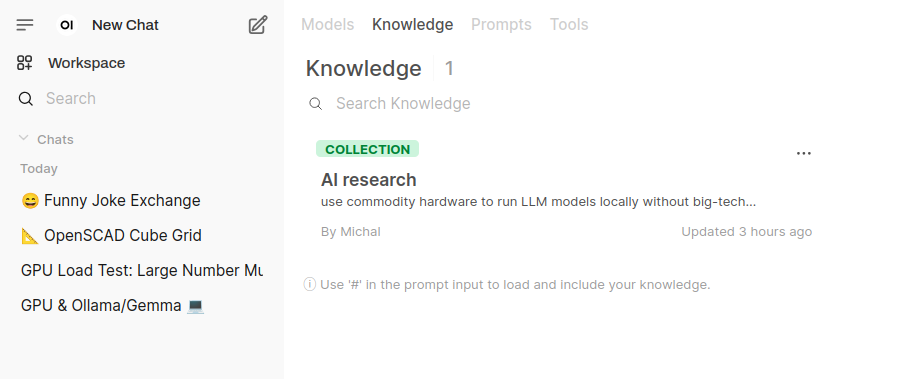
Knowledge base/context
You can build your knowledge context where you can add your knowledge entries. Probably useful when creating custom chat bots.
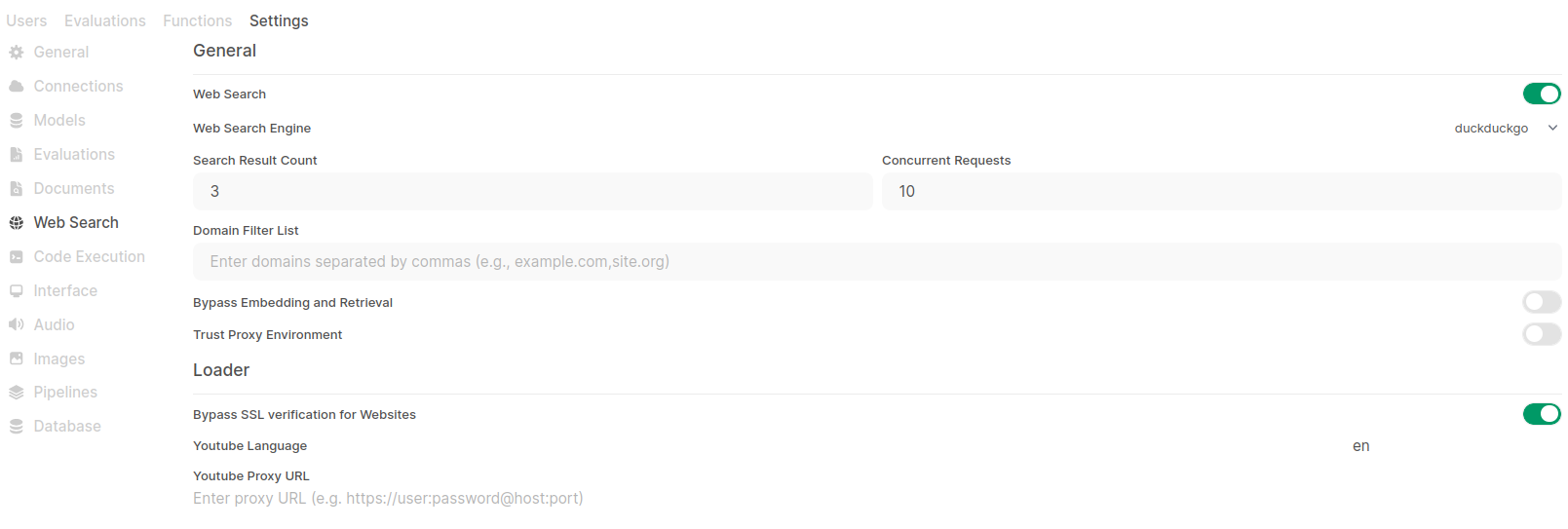
Web search
There is also web search feature. You can define you preferred search engine.
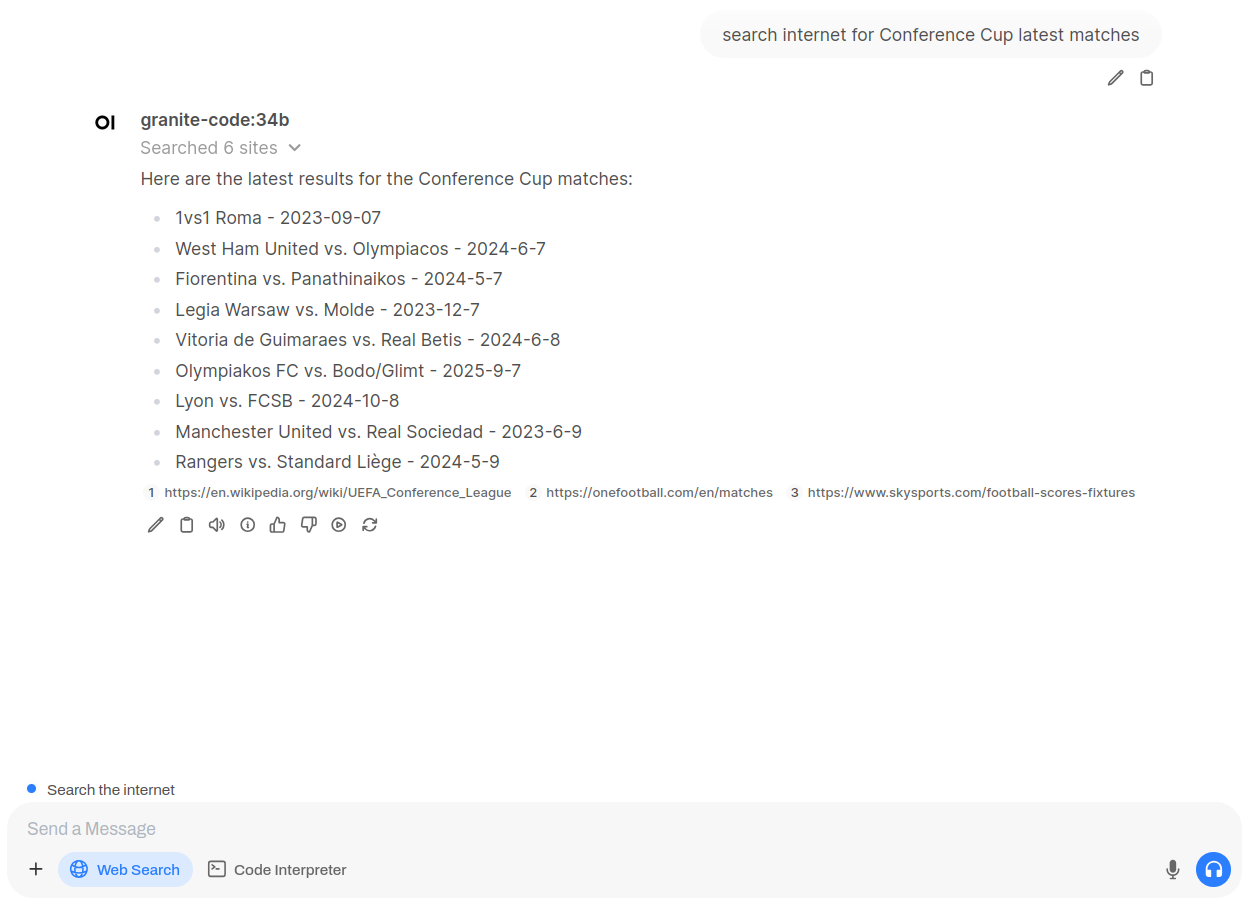
Once set, start new chat and enable search. It will search thru internet for required information. Although it looks funny:
Conclusion
You can use commodity, consumer grade hardware to run your local LLMs with Ollama, even those much more resource hungry by combining multiple GPUs in your machine. Distributed inference with Ollama and Exo requires little more work to be done. I will be searching for further tools across this vast sea of possiblities.