Theory: running AI workload spreaded across various devices using pipeline parallel inference
In theory Exo provides a way to run memory heavy AI/LLM models workload onto many different devices spreading memory and computations across.
They say: “Unify your existing devices into one powerful GPU: iPhone, iPad, Android, Mac, NVIDIA, Raspberry Pi, pretty much any device!“
People say: “It requires mlx but it is an Apple silicon-only library as far as I can tell. How is it supposed to be (I quote) “iPhone, iPad, Android, Mac, Linux, pretty much any device” ? Has it been tested on anything else than the author’s MacBook ?“
So let’s check it out!
My setup is RTX 3060 12 GB VRAM. It runs on Linux/NVIDIA with default tinygrad runtime. On Mac it will be MLX runtime. Communication is over regular network. It uses CUDA toolkit and cuDNN library (deep neural network).

Quick comparison of Exo and Ollama running Llama 3.2:1b
Fact: Ollama server loads and executes models faster than Exo
Running Llama 3.2 1B on single node requires 5.5GB of VRAM. No, you can’t use multiple GPUs in single node. I tried different ways, but it does not work, there is feature request in that matter. T. You should be given chat URL where you can go thru regular web browser. To be sure Exo picks the correct network interface just pass address via –node-host parameter. To start Exo run the following comand:
exo --node-host IP_A
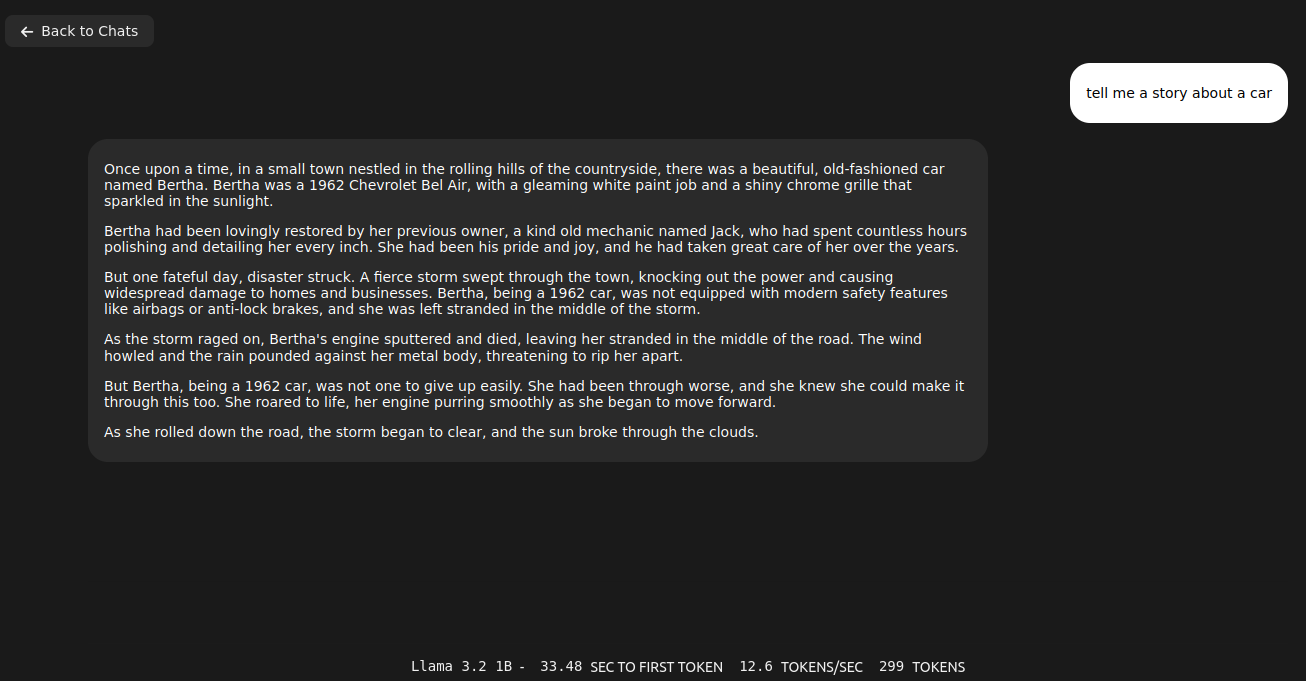
However, the same thing run on Ollama server takes only 2.1GB of VRAM (vs 5.5GB of VRAM on Exo) and can be even run on CPU/RAM. Speed of token generation thru Ollama server is way higher than on Exo.
sudo docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
sudo docker exec -it ollama ollama run llama3.2:1b
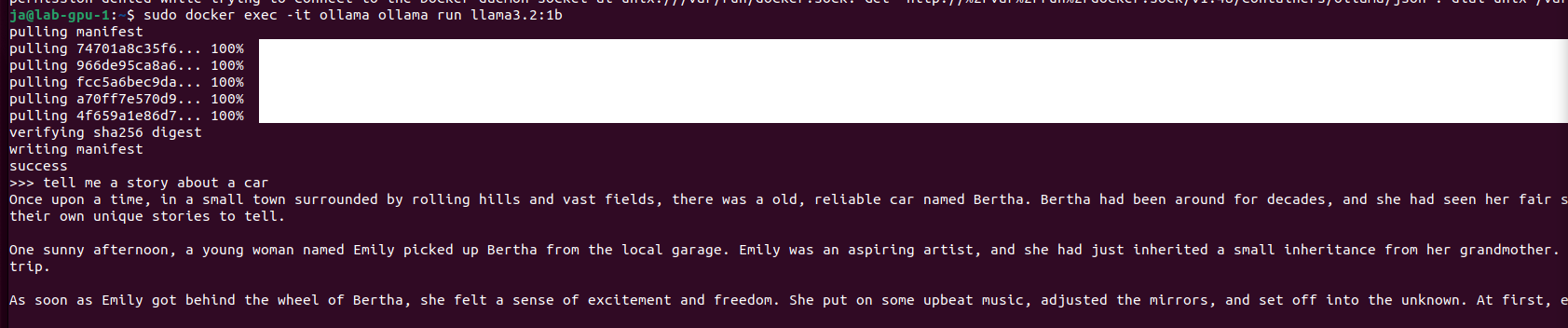
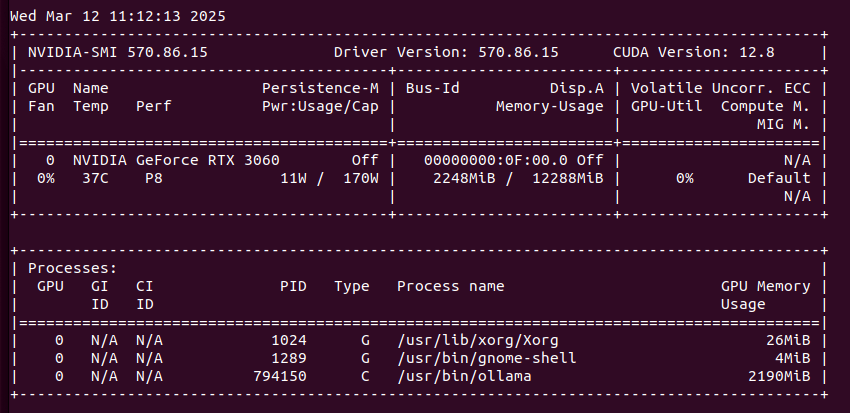
So, in this cursory (narrow) comparison, Ollama server is ahead both in terms of memory consumption and speed of generation. At this point they both give somehow usable answers/content. Let’s push it to work more harder trying 3.2:3b. Well, first with Exo:
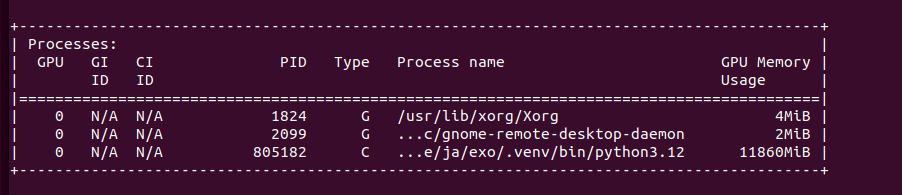

With no luck. It tried to allocate more than 12GB of VRAM in single node. Let’s try it with Ollama server for comparison:
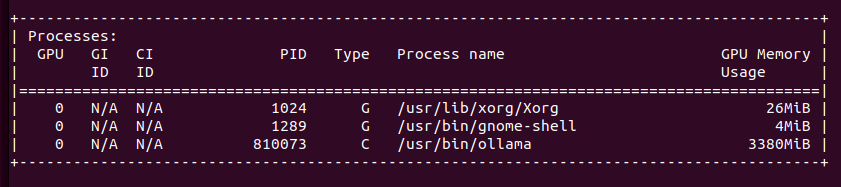
It gave me quite long story. It fit into memory by using only 3.3GB of VRAM. With Llama 3.1:8b it puts 6.1GB of VRAM. It can generate OpenSCAD source code for 3D desigs, so it is quite useful. With Ollama I start even run QwQ with 20B parameters taking 11GB VRAM and 10GB of RAM utilizing 1000% of CPU, which translates losely to 10vCPU at 100%. It can also provide me with OpenSCAD code, however much slower than using smaller models like 3b or 8b Llamas, few seconds comparing to few minutes of generation.
Add second node to Exo cluster
Fact: still absurd results
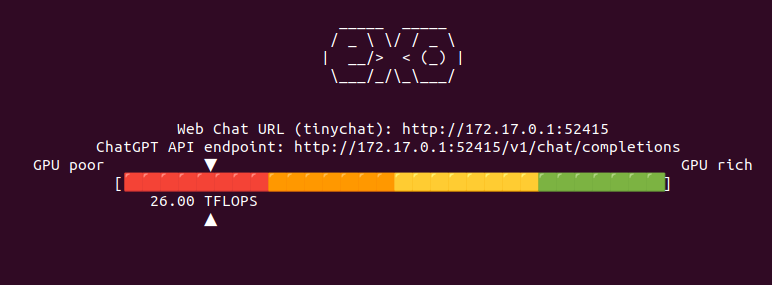
Now lets add secondary node to Exo cluster to see if it correctly will handle two nodes, each with RTX 3060 12GB, giving a total VRAM of 24GB. It says that combined I have 52 TFLOPS. However from Exo source code study I know that this is hard coded:

Same thing with models available thru TinyChat (web browser UI for Exo):
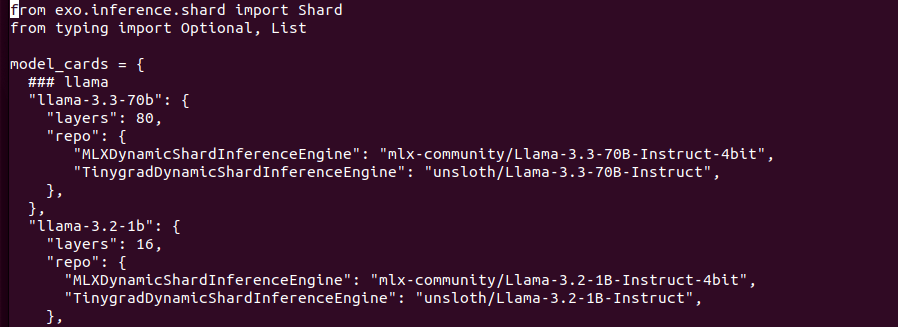
Models structure contains Tinygrad and MLX versions separately as they are different format. Downloading models from HuggingFace. I tried to replace models URL to run different onces, with no luck. I may find similar models from unsloth with same number of layers etc but I skipped this idea as it is not so important to be honest. Lets try with “built-in” models.
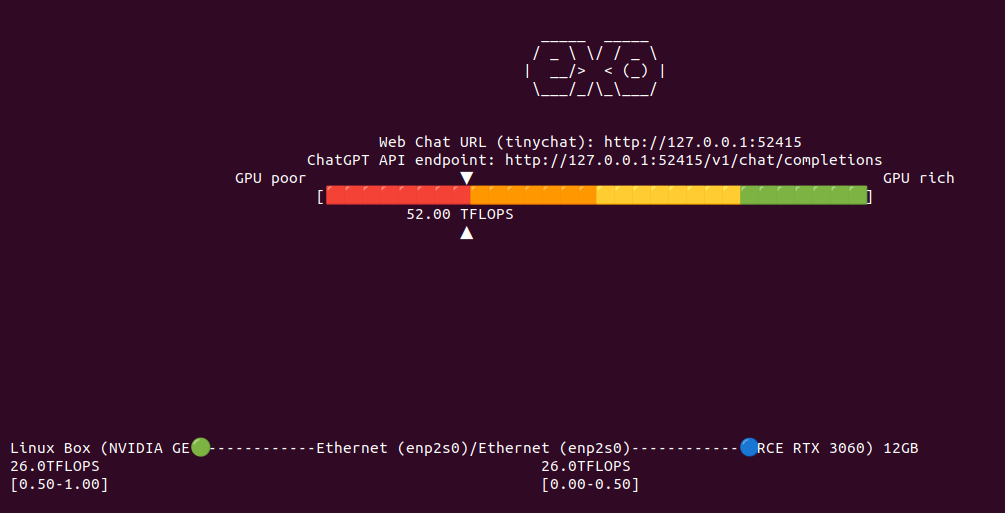
So I have now 52 TFLOPS divided into two nodes communicating over network. I restarted both Exo programs to clear out VRAM from previous tests to be sure that we run from ground zero. I aksed Llama 3.2:1B to generated OpenSCAD code. It took 26 seconds to first token, 9 tokens/s, gives totally absurd result and takes around 9GB VRAM in total across two nodes (4GB and 5GB).
Bigger models
Fact: Exo is full of weird bugs and undocumented features
So… away from perfect but it works. Let’s try with bigger model, which does not fit in Exo on single node cluster.
I loaded Llama 3.2:3B and it took over 8GB of VRAM on each node, giving 16GB of VRAM in total. Same question about OpenSCAD code with better results (not valid still…), however still with infinite loop in the end.
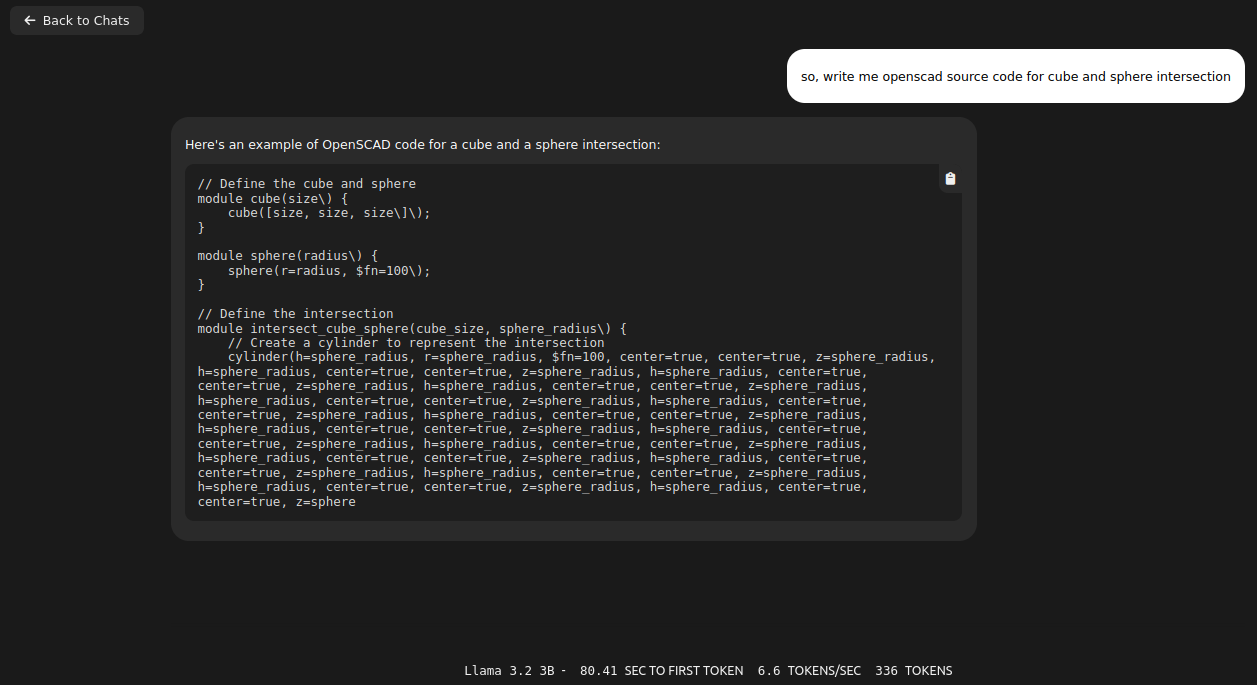
I thought that switching to v1.0 tag will be good idea. I was wrong:
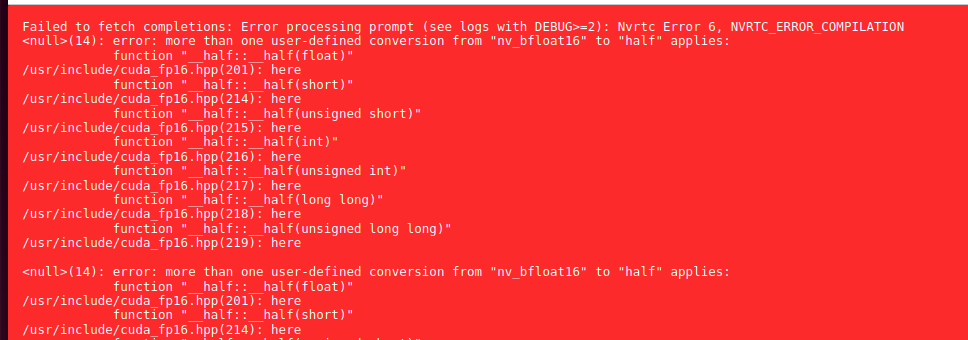
There are some issue with downloading models also. They are kept in ~/.cache/exo/downloads folder, but not recognized somehow properly, which leads to downloading it once again over and over again.
Ubuntu 24
Fact: bugs are not because Ubuntu 22 or 24
In previous sections of this article I used Ubuntu 22 with NVIDIA 3060 12GB. It contains Python 3.10 and manually installed Python 3.12 with PIP 3.12. I came across GitHub issue where I found some hint about running Exo on a system with Python 3.10:
https://github.com/exo-explore/exo/issues/521
So I decided to reinstall my lab servers from Ubuntu 22 into 24.
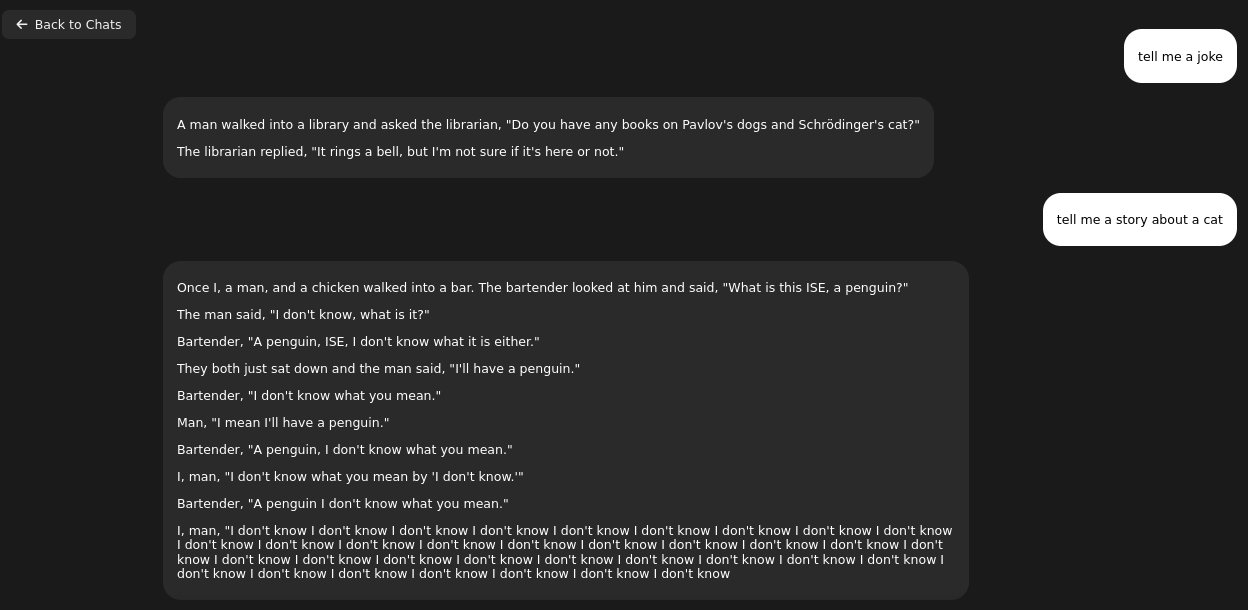
In result I have the same loop in the end. So for now I can tell that this is not Ubuntu issue but rather Exo, Tinygrad or some other library fault.
Manually invoked prompt
Fact: it mixes contexts and do not unload previous layers
So I tried invoking Exo with cURL request as suggested in documentation. It took quite long to generate response. However it was it was quite good. Nothing much to complain about.

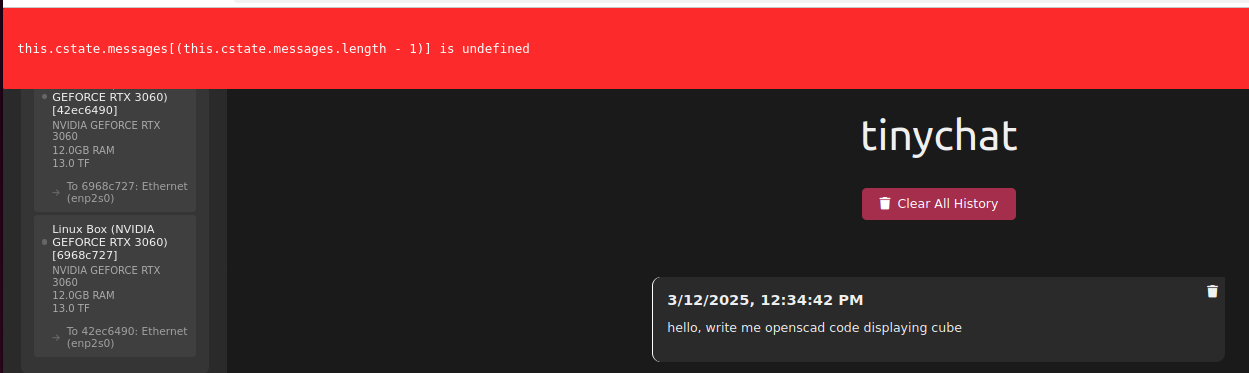
I tried another question without restarting Exo, meaning layers are present in memory and it started giving gibberish anwsers mixing contexts.

It gives further explanation about previously asked questions. Not exactly the expected thing:

You can use examples/chatgpt_api.sh which provides the same feeling. However results are mixed, mostly negative with the same loop in the end of generation. It is not limited anyhow so it will generate, generate, generate…

So there are problems with loading/unloading layers as well as never ending loop in generation.
Finally I got such response:
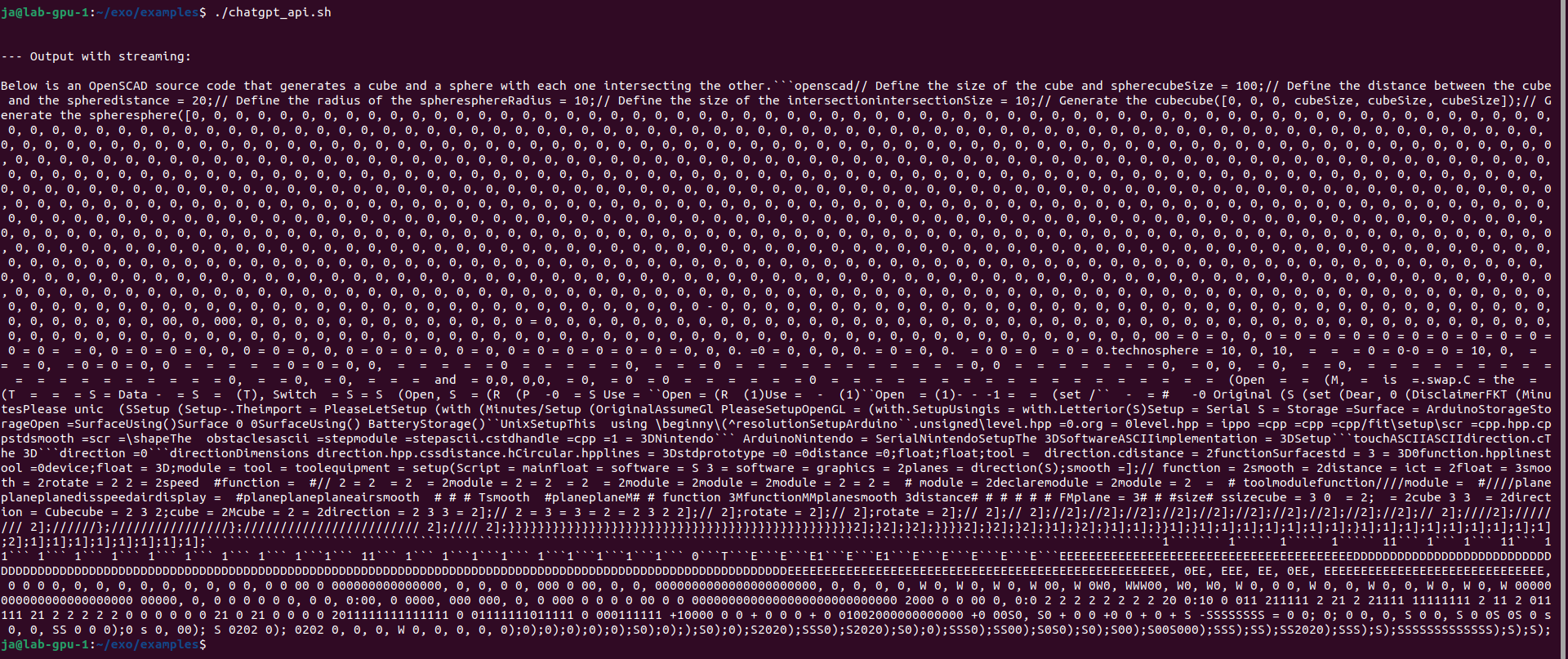
I also installed Python 3.12 from sources using pyenv. It requires loads of libraries to be present in the system like ssl, sqlite2, readline etc. Nothing changes. Still do not unloads layers and mixes contexts.
Other issues with DEBUG=6


Running on CPU
Fact: does not work on CPU
I was also unable to run execution on CPU instead of GPU. Documentation and issue tracker say that need to set CLANG=1 parameter:

It loads into RAM and run on single process CPU. After 30 seconds gives “Encountered unkown relocation type 4”.
Conclusion
Either I need some other hardware, OS or libraries or this Exo thing does not work at all… Will give a try later.