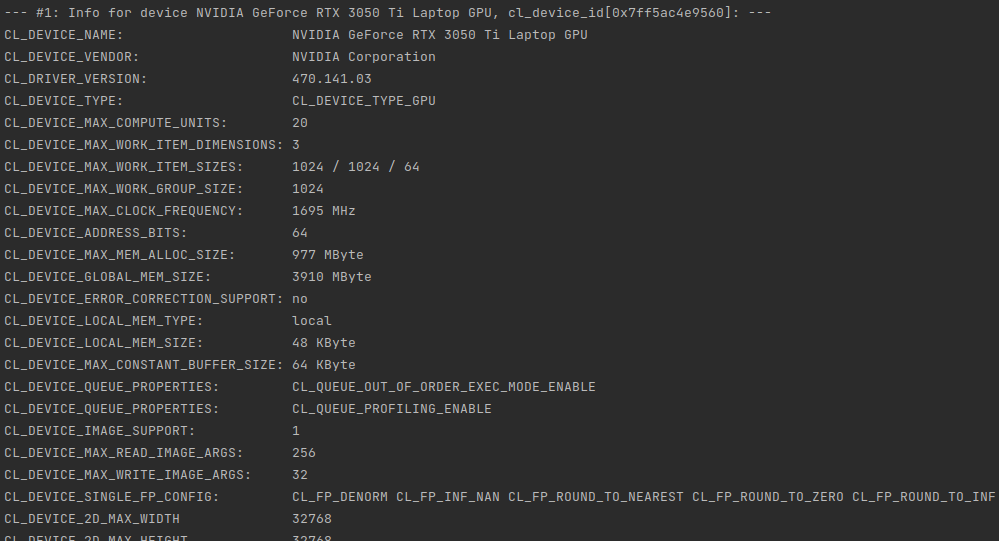
OpenCL is excellent in the field of numbers, but not that much into text processing. It lacks even basic functions available in regular C99. So the question is if it is worth trying to process some text in it.
In my OpenCL base project (which can be found here) I’ve added “aiml” module. It loads over 31k lines of text with over 4 mln characters. The text itself is in the first buffer of uchar array. Second buffer holds pointers and lenghts of consecutive lines being work-items, so there are over 31k of such work-items. Third buffer is a result array when I can store a outcome of kernel processing.
Java base code
First read text file and generate pointers and lenghts:
public void readFile() {
System.out.println(" - Read file");
File file = new File("aiml/src/com/michalasobczak/aiml/bible.txt");
try {
BufferedReader br = new BufferedReader(new FileReader(file));
String st = null;
while ((st = br.readLine()) != null) {
allstring.append(st);
vector.add(st);
line_sizes.add(pointer);
pointer = pointer + st.length();
counter++;
}
} catch (IOException e) {
throw new RuntimeException(e);
}
System.out.println("Read no of lines: " + counter);
System.out.println("sample line: " + vector.get(100));
System.out.println("sample line size in chars: " + line_sizes.get(5));
n = counter;
}
And then copy source text, pointers and lenghts to thebuffers:
public void generateSampleRandomData() {
System.out.println(" - Started sampling data");
for (int i=0; i<allstring.length(); i++) {
srcArrayA[i] = (byte)allstring.charAt(i);
}
System.out.println("allstring size: " + allstring.length());
for (int i=0; i<n; i++) {
srcArrayB[i*2] = line_sizes.get(i);
srcArrayB[(i*2)+1] = vector.get(i).length();
}
System.out.println(" - Finished sampling data");
}
Buffers are as follows:
public void createBuffers() {
// Allocate the memory objects for the input- and output data
this.memObjects[0] = clCreateBuffer(this.context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, (long) Sizeof.cl_uchar * this.allstring.length(), KernelConfigurationSet.srcA, null);
this.memObjects[1] = clCreateBuffer(this.context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, (long) Sizeof.cl_int * this.n * 2, KernelConfigurationSet.srcB, null);
this.memObjects[2] = clCreateBuffer(this.context, CL_MEM_READ_WRITE, (long) Sizeof.cl_uchar * this.n, null, null);
}
Kernel code is divided into two parts:
public void readKernelFile() {
this.content = new String("");
try {
this.content = Files.readString(Path.of("aiml/src/com/michalasobczak/aiml/utils.c"));
this.content += "\n";
this.content += Files.readString(Path.of("aiml/src/com/michalasobczak/aiml/kernel.c"));
} catch (IOException e) {
e.printStackTrace();
}
}
In terms of Java base code that is all.
C99 kernel code
As I have already mentioned, OpenCL C99 lacks of several basic text processing features. I think that is because it is not meant to be used with texts and secondly because you cannot do recursion and I suspect that some of those functions might use it. So I decided to prepare some basic functions as follows:
#define MAX_STRING_SIZE 256
int get_string_size(uchar string[]) {
int size;
int c;
int counter = 0;
for (c=0; c<MAX_STRING_SIZE; c++) {
if (string[c] == NULL) {
break;
}
counter++;
}
return counter;
}
void print_string(uchar stringa[]) {
int size = get_string_size(stringa);
int c;
for (c=0; c<size; c++) {
printf("%c", stringa[c]);
}
printf("\n");
}
void set_string(uchar wb[], uchar tmp[]) {
int c;
int size = get_string_size(tmp);
for (c=0; c<size; c++) {
wb[c] = tmp[c];
}
}
void set_string_and_print(uchar wb[], uchar tmp[]) {
set_string(wb, tmp);
print_string(wb);
}
int find_string_in_string(uchar source[], uchar looking_for[]) {
int s_size = get_string_size(source);
int lf_size = get_string_size(looking_for);
int c, d;
for (c=0; c<s_size; c++) {
for (d=0; d<lf_size; d++) {
if (source[c+d] == looking_for[d]) {
;
}
else {
break;
}
if (d == lf_size-1) {
return 1;
}
}
}
return 0;
}
Few words of explanation. String size function relies on NULL terminated characters array. String setter function does not puts that NULL in the end, so you need to do it yourself if needed. Finding string in string returns only first hit.
Now, the kernel:
__kernel void sampleKernel(__global const uchar* srcA,
__global const int2* srcB,
__global uchar* dst)
{
int gc, ls, gs, gid, lid;
int c, d;
int res = 0;
__private uchar current[131*1000] = { '\0' };
__private uchar word_buffer[30] = { '\0' };
// -- PROCEDURE
gid = get_global_id(0);
int2 val = srcB[gid];
d = 0;
// prepare current local item
for (c=val.s0; c<val.s0+val.s1; c++) {
current[d] = srcA[c];
d++;
} // for
uchar tmp[10] = "LORD\0";
set_string(word_buffer, tmp);
res = find_string_in_string(current, word_buffer);
dst[gid] = res;
} // kernel
As shown before in Java base code, there are 3 buffers. First one is for plain uchar array of source text. Second one is for int2 vectors holding pointers and lenghts of consecutive, adjacent lines/verses. Third is for output data, for instance in case of successful search it holds 1, otherwise 0.
I’ve tested this on my NVIDIA GeForce RTX 3050 Ti Mobile with 4 GB of VRAM. Having around 32k elements (work-items) means that we can allocate as much as 131kB of data per single work-item. This way we can fully load all available VRAM memory. Of source not all of given work-items will be run at the same time because there is only 2560 cores in this GPU. So obiously it is the maximum parallel items working at the “same time”. Estimated 13 rounds is required to process all the data, however we need to keep in mind that local-size is set to 32 and there are some specific constraints put on the GPU itself by CC (compute capabilities) specifications.
For CC 8.6 we have maximum of 16 thread blocks per SM (streaming multiprocessor) times 32 work-items of local-work-size it gives us 512 max. RTX 3050 Ti has 20 SM, so the maximum simultaneous (in theory) working items would be 10240, but having only 2560 cores I think that of course it will not reach that far having 100% utilization at much lower values. Still for the latest GPUs, they can have up to 16k cores, so that kind of hardware could better utilize CC 8.6 of higher specification on full load.
I would like to point out one more things regarding private/register memory and a global memory. In case of Ampere GPU architecture:
- The register file size is 64K 32-bit registers per SM.
- The maximum number of registers per thread is 255.
So, we are limited per work-item to 255 registers and there is also a 64k limit per SM. We can thus estimate or even calculate the maximum data size which will fit locally and beyond that value it will go outside to global memory providing much higher latency. It can be seen on times calculation increasing while we increase uchar current array.
Conclusion
Text processing in OpenCL works just fine with 0 – 1 ms per single search thru over 4 mln characters (31-32k lines). We are constrained by lack of string or memory functions so all string function I’ve made use constant array buffers. I’ve practically tested full VRAM allocation (4GB). Power draw is 51W.
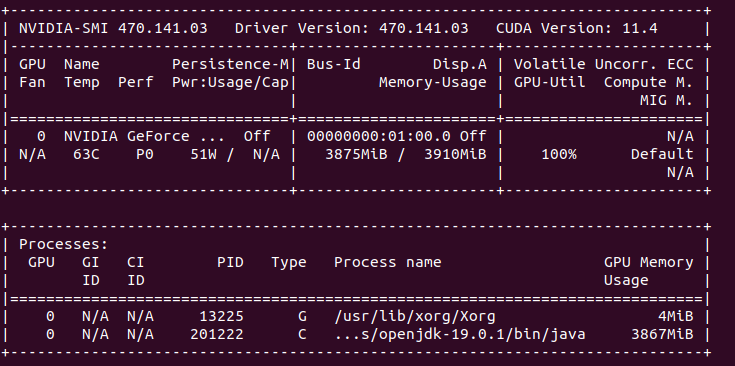
What next? I think that may take step forward and try to do come classification and few other things toward ML or even AI. That can be quite interesting to see…